Overview
As a programmer, you can consider a feature, in machine learning, to be a variable associated with some entity that contains a value that is useful for helping train a model to solve a prediction problem. That is, the feature is just a variable with predictive power for a machine learning problem, or task.
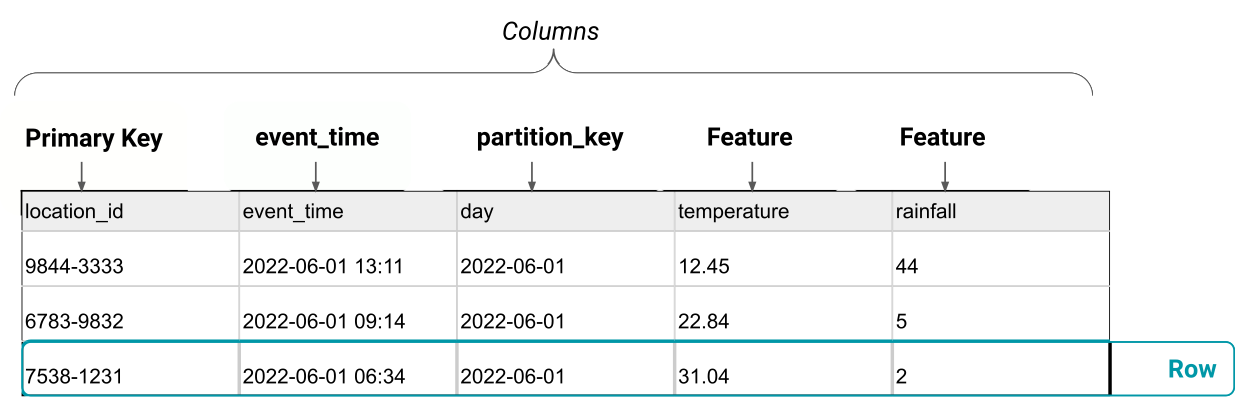
A feature group is a table of features, where each feature group has a primary key, and optionally an event_time column (indicating when the features in that row were observed), and a partition key. Collectively, they are referred to as columns. The partition key determines how to layout the feature group rows on disk such that you can efficiently query the data using queries with the partition key. For example, if your partition key is the day and you have hundreds of days worth of data, with a partition key, you can query the day for only a given day or a range of days, and only the data for those days will be read from disk.
Online and offline Storage#
Feature groups can be stored in a low-latency "online" database and/or in low cost, high throughput "offline" storage, typically a data lake or data warehouse. The online store stores only the latest values of features for a feature group. It is used to serve pre-computed features to models at runtime. The offline store stores the historical values of features for a feature group, so it may store many times more data than the online store. Offline feature groups are used, typically, to create training data for models, but also to retrieve data for batch scoring of models:
