Spark Integration#
Connecting to the Feature Store from an external Spark cluster, such as Cloudera, requires configuring it with the Hopsworks client jars and configuration. This guide explains step by step how to connect to the Feature Store from an external Spark cluster.
Download the Hopsworks Client Jars#
In the Project Settings, select the integration tab and scroll to the Configure Spark Integration section. Click on Download client Jars. This will start the download of the client.tar.gz archive. The archive contains two jar files for HopsFS, the Apache Hudi jar and the Java version of the HSFS library. You should upload these libraries to your Spark cluster and attach them as local resources to your Job. If you are using spark-submit, you should specify the --jar option. For more details see: Spark Dependency Management.
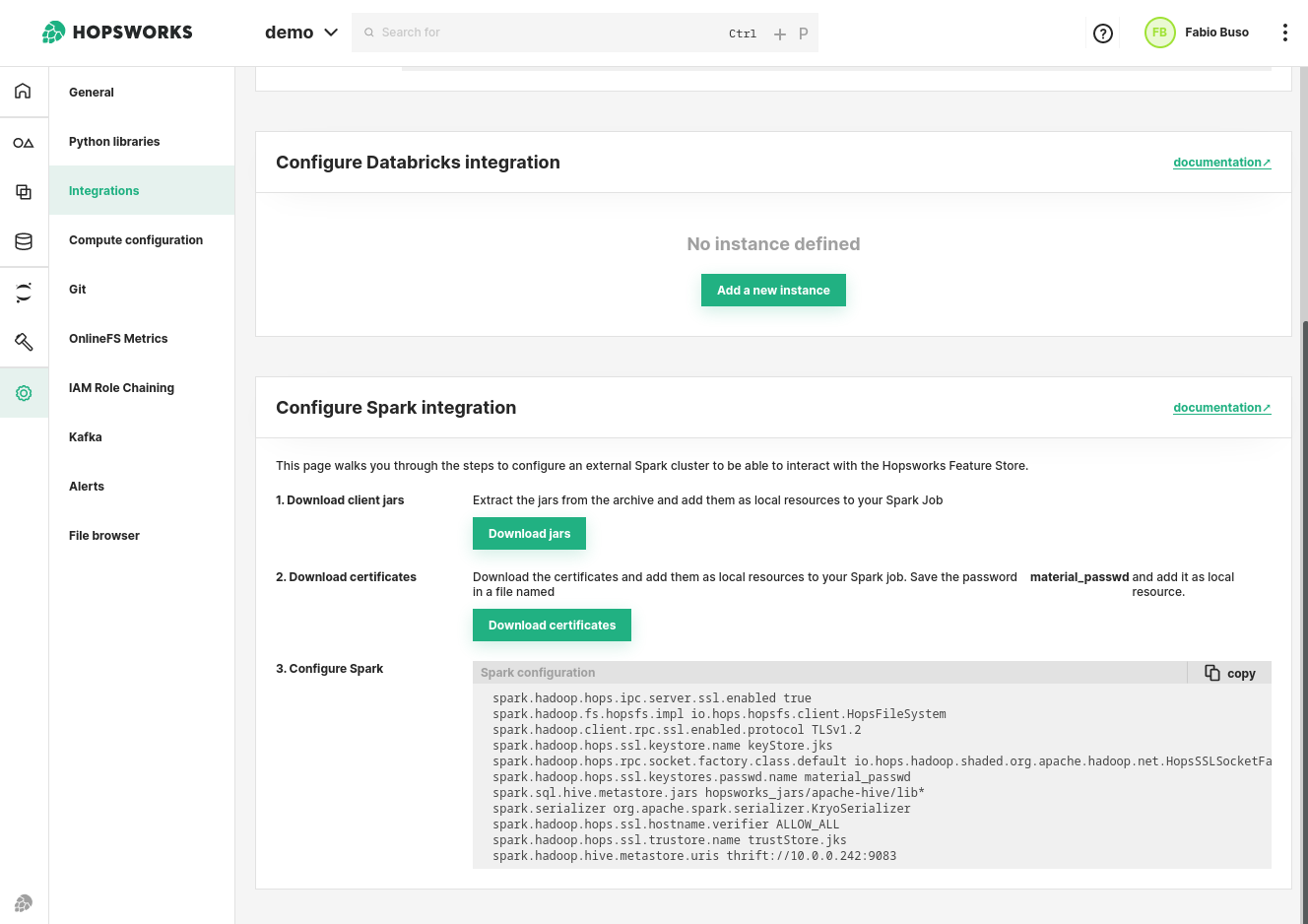
Download the certificates#
Download the certificates from the same section as above. Hopsworks uses X.509 certificates for authentication and authorization. If you are interested in the Hopsworks security model, you can read more about it in this blog post. The certificates are composed of three different components: the keyStore.jks containing the private key and the certificate for your project user, the trustStore.jks containing the certificates for the Hopsworks certificates authority, and a password to unlock the private key in the keyStore.jks. The password is displayed in a pop-up when downloading the certificate and should be saved in a file named material_passwd.
Warning
When you copy-paste the password to the material_passwd file, pay attention to not introduce additional empty spaces or new lines.
The three files (keyStore.jks, trustStore.jks and material_passwd) should be attached as resources to your Spark application as well.
Configure your Spark cluster#
Add the following configuration to the Spark application:
spark.hadoop.fs.hopsfs.impl io.hops.hopsfs.client.HopsFileSystem
spark.hadoop.hops.ipc.server.ssl.enabled true
spark.hadoop.hops.ssl.hostname.verifier ALLOW_ALL
spark.hadoop.hops.rpc.socket.factory.class.default io.hops.hadoop.shaded.org.apache.hadoop.net.HopsSSLSocketFactory
spark.hadoop.client.rpc.ssl.enabled.protocol TLSv1.2
spark.hadoop.hops.ssl.keystores.passwd.name material_passwd
spark.hadoop.hops.ssl.keystore.name keyStore.jks
spark.hadoop.hops.ssl.trustore.name trustStore.jks
spark.sql.hive.metastore.jars path
spark.sql.hive.metastore.jars.path [Path to the Hopsworks Hive Jars]
spark.hadoop.hive.metastore.uris thrift://[metastore_ip]:[metastore_port]
spark.sql.hive.metastore.jars.path should point to the path with the jars from the uncompressed Hive archive you can find in clients.tar.gz.
PySpark#
To use PySpark, install the HSFS Python library which can be found on PyPi.
Matching Hopsworks version
The major version of HSFS needs to match the major version of Hopsworks.
Generating an API Key#
For instructions on how to generate an API key follow this user guide. For the Spark integration to work correctly make sure you add the following scopes to your API key:
- featurestore
- project
- job
- kafka
Connecting to the Feature Store#
You are now ready to connect to the Hopsworks Feature Store from Spark:
import hsfs
conn = hsfs.connection(
host='my_instance', # DNS of your Feature Store instance
port=443, # Port to reach your Hopsworks instance, defaults to 443
project='my_project', # Name of your Hopsworks Feature Store project
api_key_value='api_key', # The API key to authenticate with the feature store
hostname_verification=True # Disable for self-signed certificates
)
fs = conn.get_feature_store() # Get the project's default feature store
Engine
HSFS uses either Apache Spark or Pandas on Python as an execution engine to perform queries against the feature store. The engine option of the connection let's you overwrite the default behaviour by setting it to "python" or "spark". By default, HSFS will try to use Spark as engine if PySpark is available, hence, no further action should be required if you setup Spark correctly as described above.
Next Steps#
For more information about how to connect, see the Connection API reference. Or continue with the Data Source guide to import your own data to the Feature Store.