How To Configure Inference Batcher#
Introduction#
Inference batching can be enabled to increase inference request throughput at the cost of higher latencies. The configuration of the inference batcher depends on the serving tool and the model server used in the deployment. See the compatibility matrix.
GUI#
Step 1: Create new deployment#
If you have at least one model already trained and saved in the Model Registry, navigate to the deployments page by clicking on the Deployments tab on the navigation menu on the left.
Once in the deployments page, click on New deployment if there are not existing deployments or on Create new deployment at the top-right corner to open the deployment creation form.
Step 2: Go to advanced options#
A simplified creation form will appear including the most common deployment fields among all the configuration possible. Inference batching is part of the advanced options of a deployment. To navigate to the advanced creation form, click on Advanced options.
Step 3: Configure inference batching#
To enable inference batching, click on the Request batching checkbox.
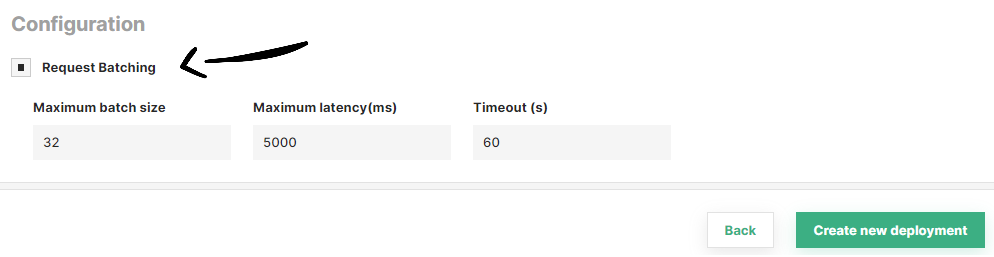
If your deployment uses KServe, you can optionally set three additional parameters for the inference batcher: maximum batch size, maximum latency (ms) and timeout (s).
Once you are done with the changes, click on Create new deployment at the bottom of the page to create the deployment for your model.
Code#
Step 1: Connect to Hopsworks#
import hopsworks
project = hopsworks.login()
# get Hopsworks Model Registry handle
mr = project.get_model_registry()
# get Hopsworks Model Serving handle
ms = project.get_model_serving()
Step 2: Define an inference logger#
from hsml.inference_batcher import InferenceBatcher
my_batcher = InferenceBatcher(enabled=True,
# optional
max_batch_size=32,
max_latency=5000, # milliseconds
timeout=5 # seconds
)
Step 3: Create a deployment with the inference batcher#
my_model = mr.get_model("my_model", version=1)
my_predictor = ms.create_predictor(my_model,
inference_batcher=my_batcher
)
my_predictor.deploy()
# or
my_deployment = ms.create_deployment(my_predictor)
my_deployment.save()
API Reference#
Compatibility matrix#
Show supported inference batcher configuration
| Serving tool | Model server | Inference batching | Fine-grained configuration |
|---|---|---|---|
| Docker | Flask | ❌ | - |
| TensorFlow Serving | ✅ | ❌ | |
| Kubernetes | Flask | ❌ | - |
| TensorFlow Serving | ✅ | ❌ | |
| KServe | Flask | ✅ | ✅ |
| TensorFlow Serving | ✅ | ✅ |