Cluster creation in managed.hopsworks.ai (GCP)#
This guide goes into detail for each of the steps of the cluster creation in managed.hopsworks.ai
Step 1 starting to create a cluster#
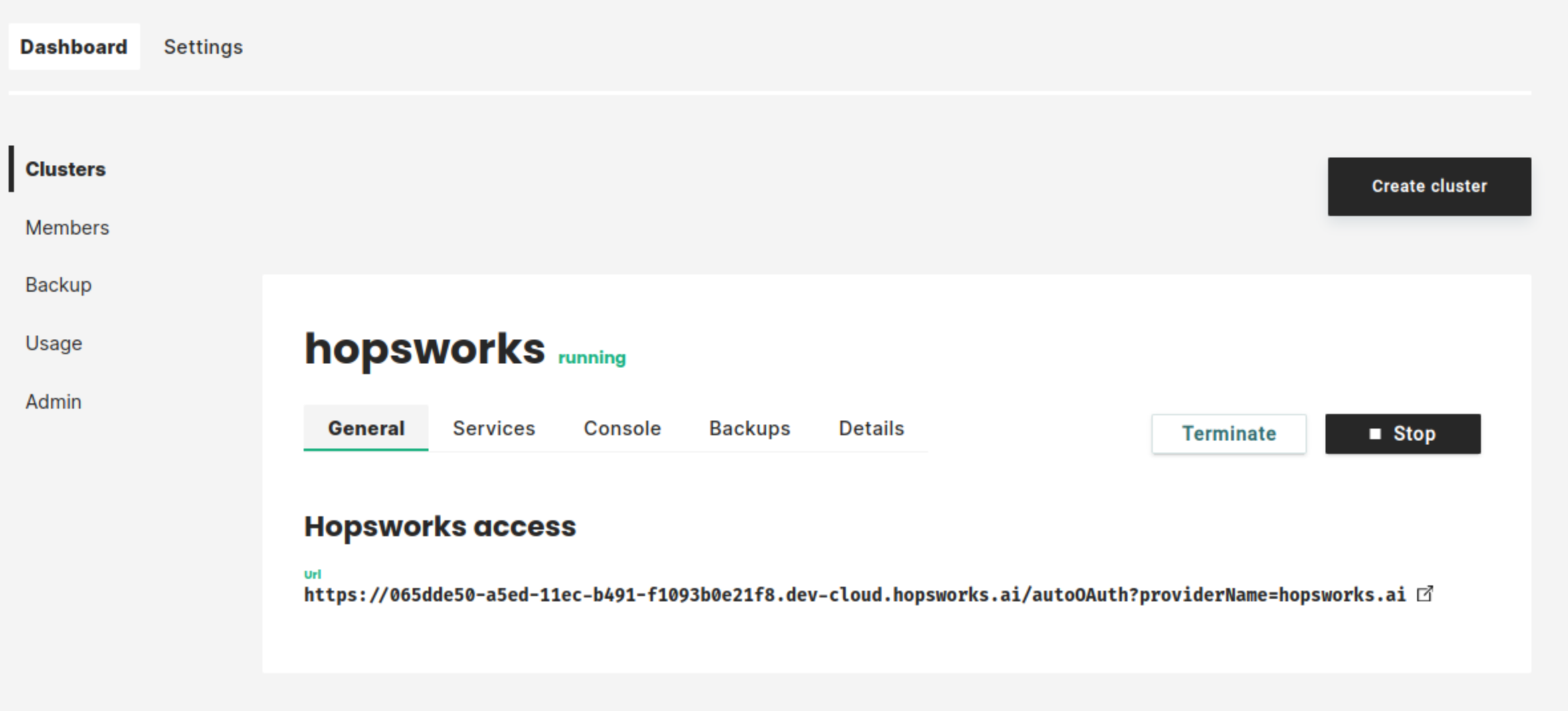
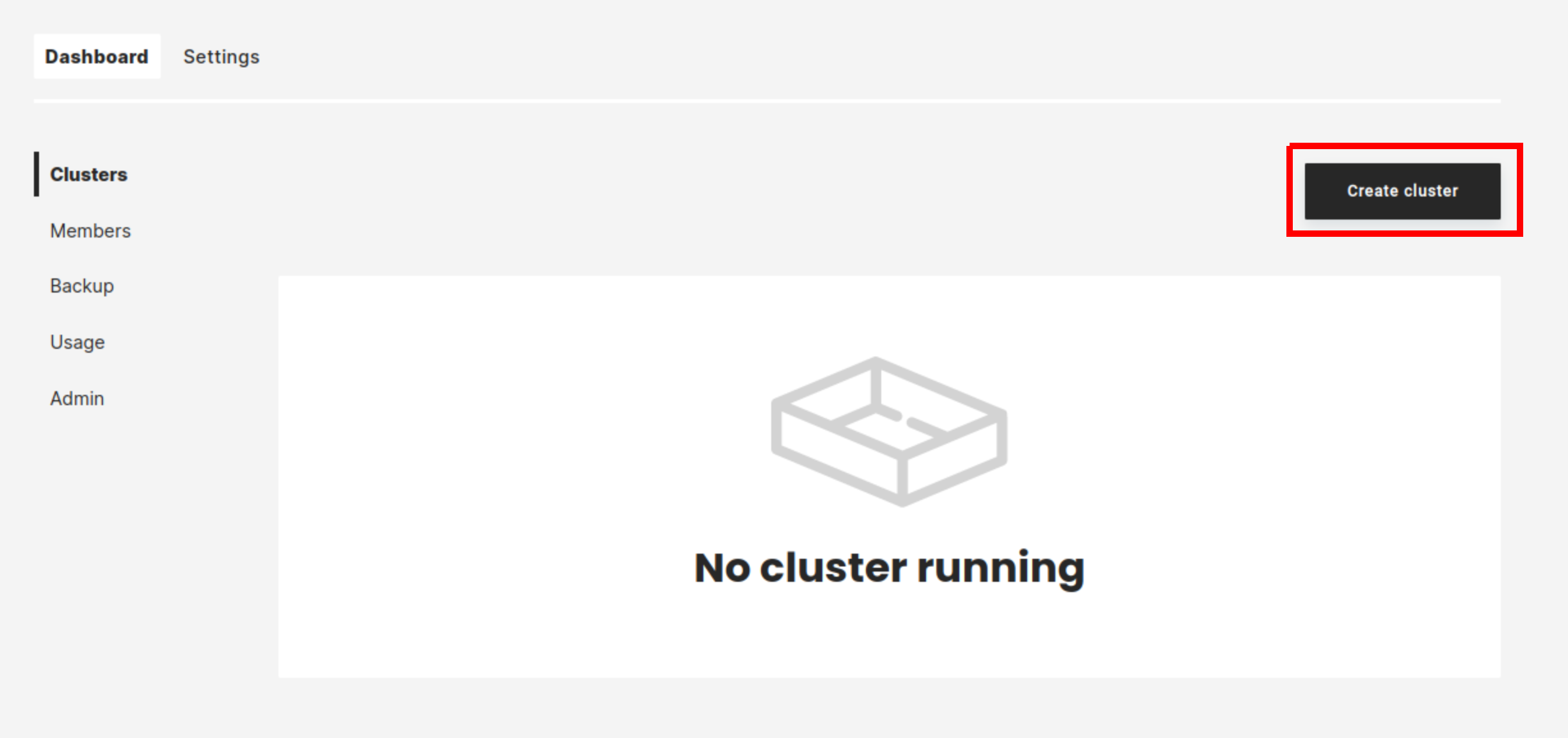
In managed.hopsworks.ai, select Create cluster:
Step 2 setting the General information#
Select the GCP Project (1) in which you want the cluster to run.
Note
If the Project does not appear in the drop-down, make sure that you properly Connected your GCP account for this project.
Name your cluster (2). Choose the Region(3) and Zone(4) in which to deploy the cluster.
Select the Instance type (5) and Local storage (6) size for the cluster Head node.
Optional: Specify a customer-managed encryption key to be used for encryption of local storage. The key has to be specified using the format: projects/PROJECT_ID/locations/REGION/keyRings/KEY_RING/cryptoKeys/KEY. Note that your project needs to be configured to allow usage of the key. This can be achieved by executing the gcloud command below. Refer to the GCP documentation for more details: Protect resources by using Cloud KMS keys.
gcloud projects add-iam-policy-binding KMS_PROJECT_ID \
--member serviceAccount:service-PROJECT_NUMBER@compute-system.iam.gserviceaccount.com \
--role roles/cloudkms.cryptoKeyEncrypterDecrypter
Enter the name of the bucket in which the Hopsworks cluster will store its data in Cloud Storage Bucket (8)
Warning
The bucket must be empty and must be in a region accessible from the region in which the cluster is deployed.
The artifact registry used to store the clusters docker images (9)

Step 3 workers configuration#
In this step, you configure the workers. There are two possible setups: static or autoscaling. In the static setup, the cluster has a fixed number of workers that you decide. You can then add and remove workers manually, for more details: documentation. In the autoscaling setup, you configure conditions to add and remove workers and the cluster will automatically add and remove workers depending on the demand, for more details: documentation.
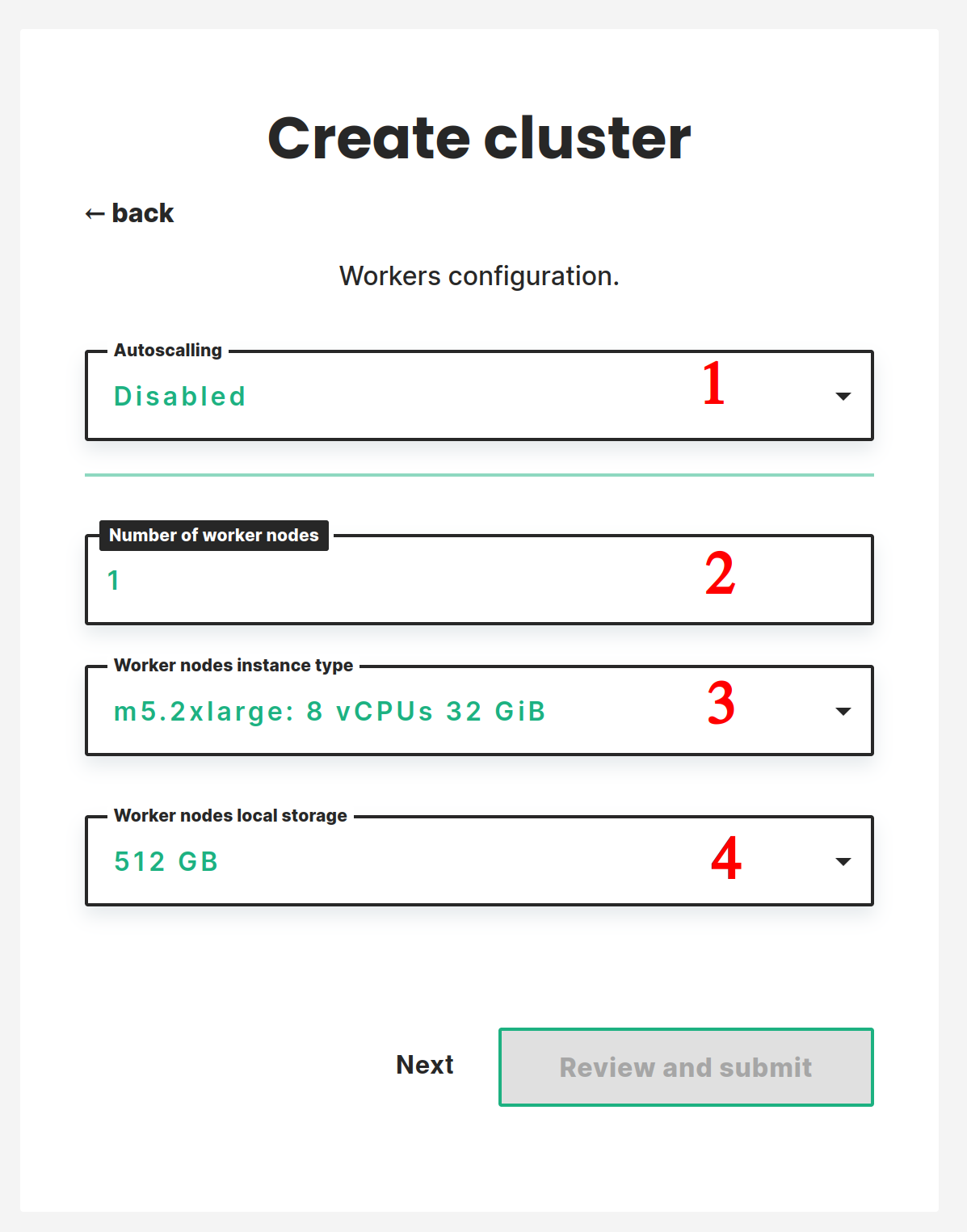
Static workers configuration#
You can set the static configuration by selecting Disabled in the first drop-down (1). Then you select the number of workers you want to start the cluster with (2). And, select the Instance type (3) and Local storage size (4) for the worker nodes.
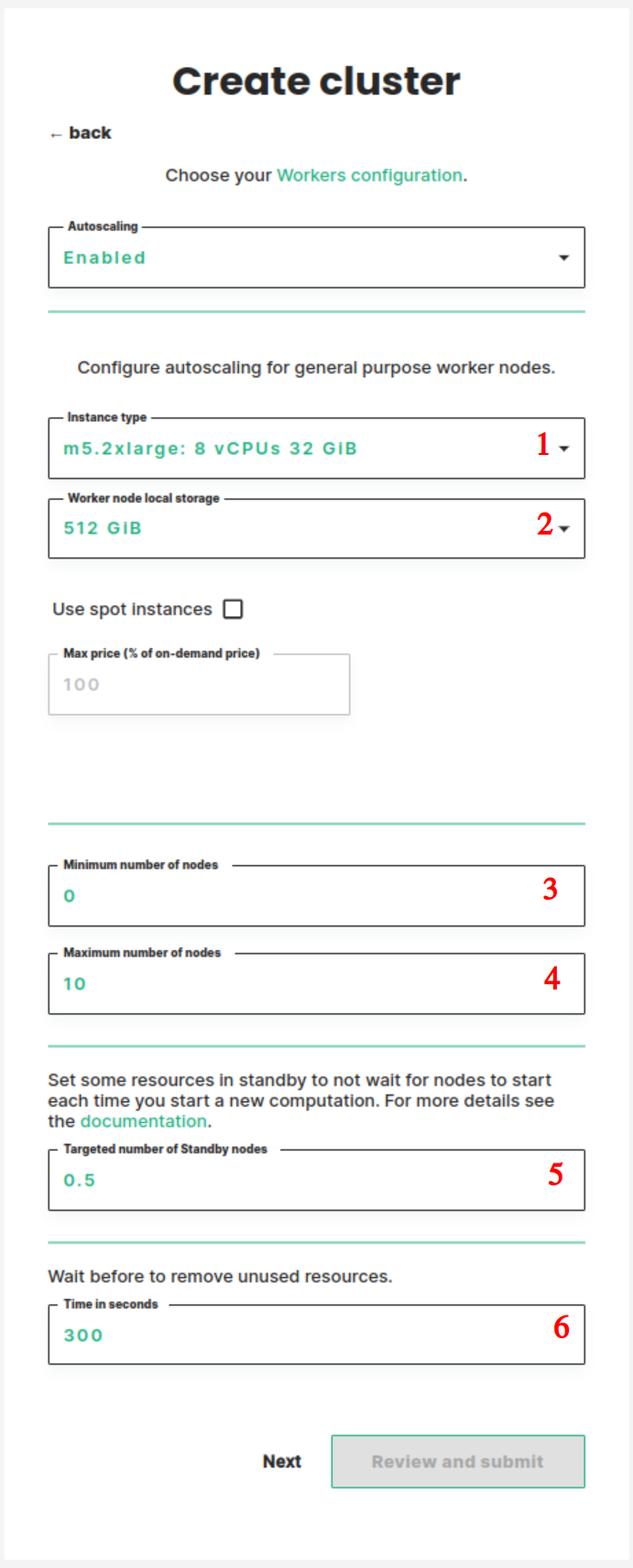
Autoscaling workers configuration#
You can set the autoscaling configuration by selecting enabled in the first drop-down (1). You can configure:
- The instance type you want to use.
- The size of the instances' disk.
- The minimum number of workers.
- The maximum number of workers.
- The targeted number of standby workers. Setting some resources on standby ensures that there are always some free resources in your cluster. This ensures that requests for new resources are fulfilled promptly. You configure the standby by setting the number of workers you want to be on standby. For example, if you set a value of 0.5 the system will start a new worker every time the aggregated free cluster resources drop below 50% of a worker's resources. If you set this value to 0 new workers will only be started when a job or notebook requests the resources.
- The time to wait before removing unused resources. One often starts a new computation shortly after finishing the previous one. To avoid having to wait for workers to stop and start between each computation it is recommended to wait before shutting down workers. Here you set the amount of time in seconds resources need to be unused before they get removed from the system.
Note
The standby will not be taken into account if you set the minimum number of workers to 0 and no resources are used in the cluster. This ensures that the number of nodes can fall to 0 when no resources are used. The standby will start to take effect as soon as you start using resources.
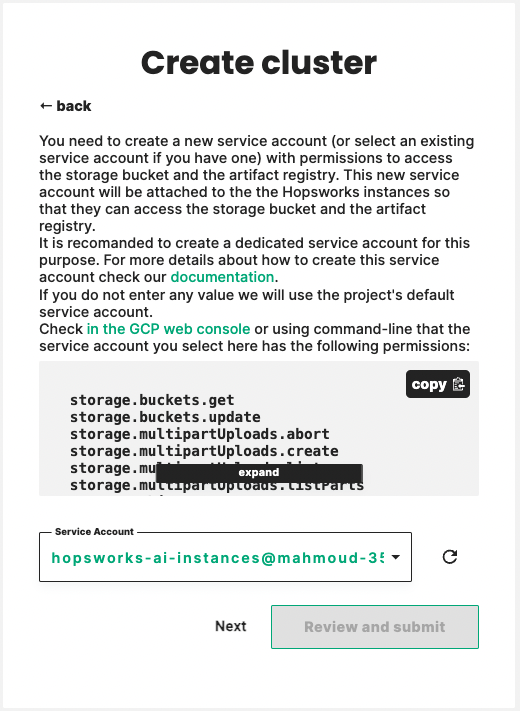
Step 4 select the Service Account#
Hopsworks cluster store their data in a storage bucket. To let the cluster instances access the bucket we need to attach a Service Account to the virtual machines. In this step, you set which Service Account to use by entering its Email. This Service Account needs to have access right to the bucket you selected in Step 2. For more details on how to create the Service Account and give it access to the bucket refer to Creating and configuring a storage
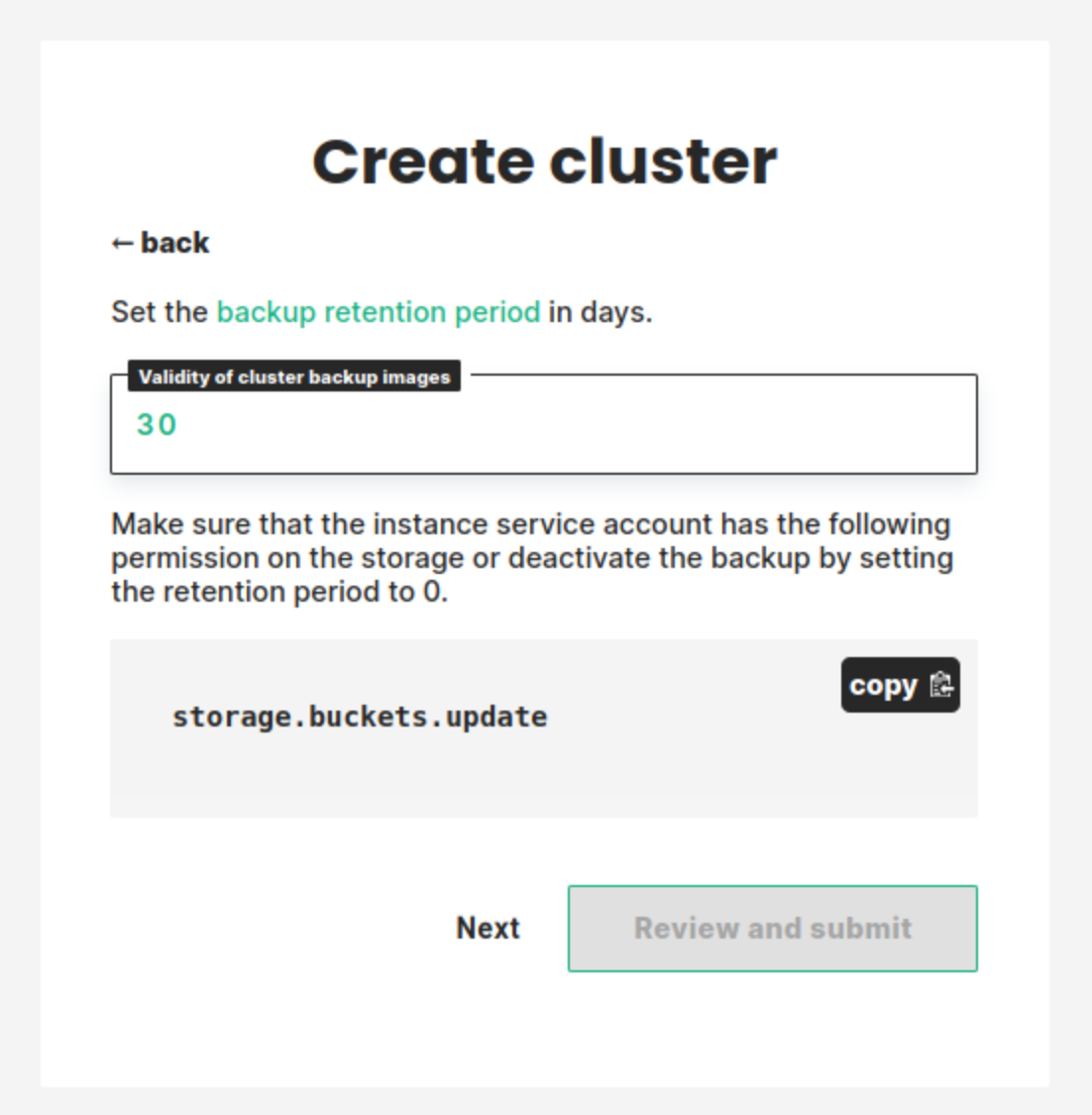
Step 5 set the backup retention policy#
To backup the storage bucket data when taking a cluster backup we need to set a retention policy for the bucket. In this step, you choose the retention period in days. You can deactivate the retention policy by setting this value to 0 but this will block you from taking any backup of your cluster.
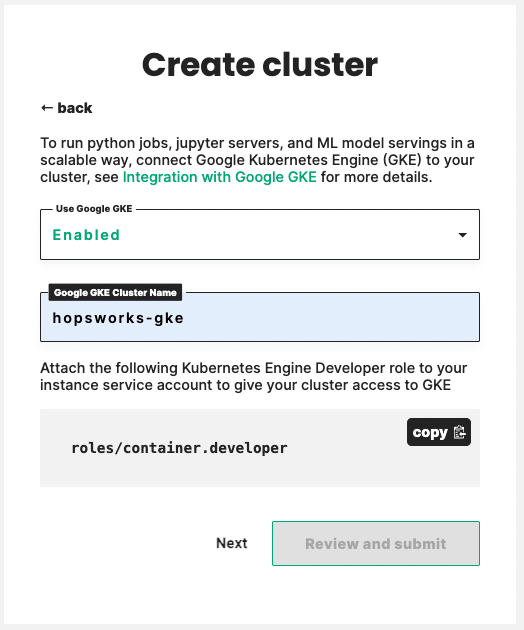
Step 6 Managed Containers#
Hopsworks cluster can integrate with Google GKE (GKE) to launch Python jobs, Jupyter servers, and ML model servings on top of Google GKE. For more detail on how to set up this integration refer to Integration with Google GKE.
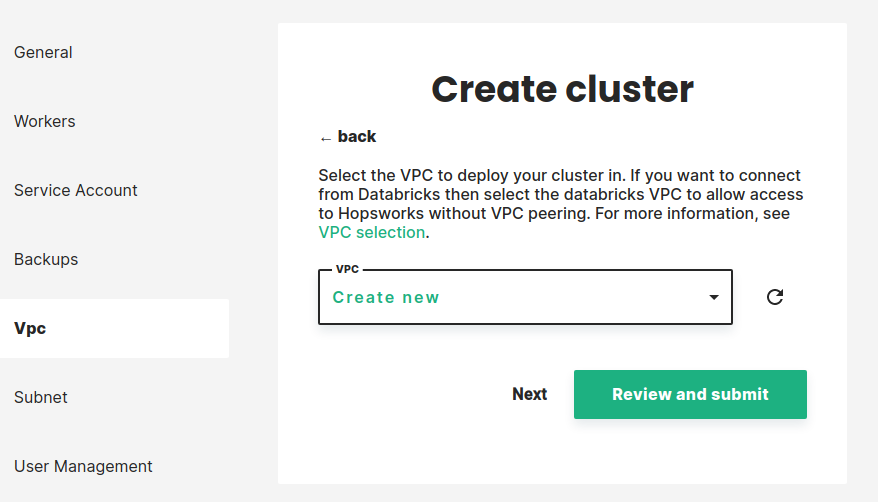
Step 7 VPC and Subnet selection#
You can select the VPC which will be used by the Hopsworks cluster. You can either select an existing VPC or let managed.hopsworks.ai create one for you. If you decide to use restricted managed.hopsworks.ai permissions (see restrictive-permissions for more details) you will need to select an existing VPC here.
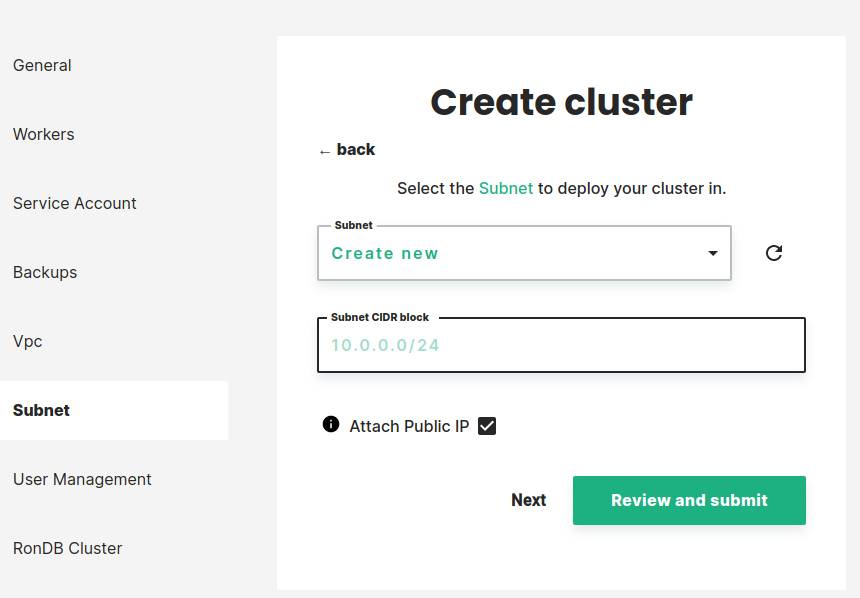
If you selected an existing VPC in the previous step, this step lets you select which subnet of this VPC to use.
If you did not select an existing virtual network in the previous step managed.hopsworks.ai will create a subnet for you. You can choose the CIDR block this subnet will use. Select the Subnet to be used by your cluster and press Next.
Step 8 User management selection#
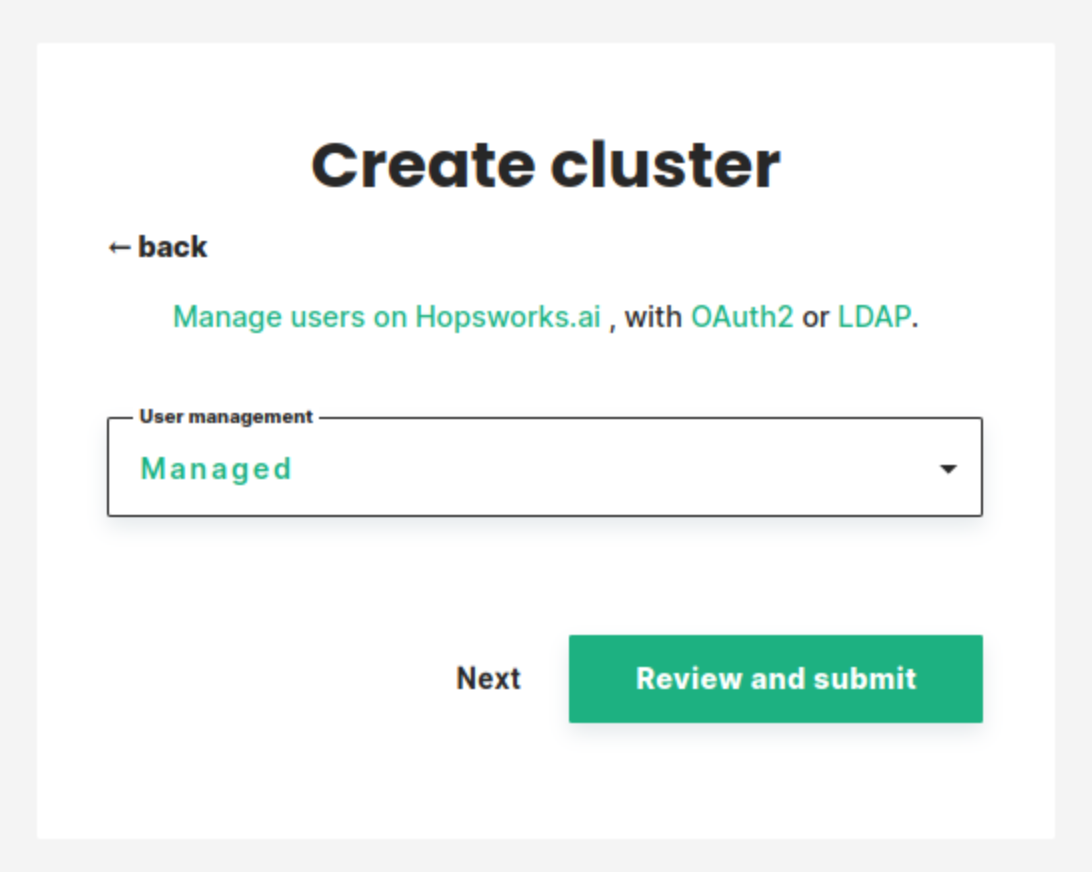
In this step, you can choose which user management system to use. You have three choices:
- Managed: managed.hopsworks.ai automatically adds and removes users from the Hopsworks cluster when you add and remove users from your organization (more details here).
- OAuth2: integrate the cluster with your organization's OAuth2 identity provider. See Use OAuth2 for user management for more detail.
- LDAP: integrate the cluster with your organization's LDAP/ActiveDirectory server. See Use LDAP for user management for more detail.
- Disabled: let you manage users manually from within Hopsworks.
Step 9 Managed RonDB#
Hopsworks uses RonDB as a database engine for its online Feature Store. By default database will run on its own VM. Premium users can scale-out database services to multiple VMs to handle increased workload.
For details on how to configure RonDB check our guide here.
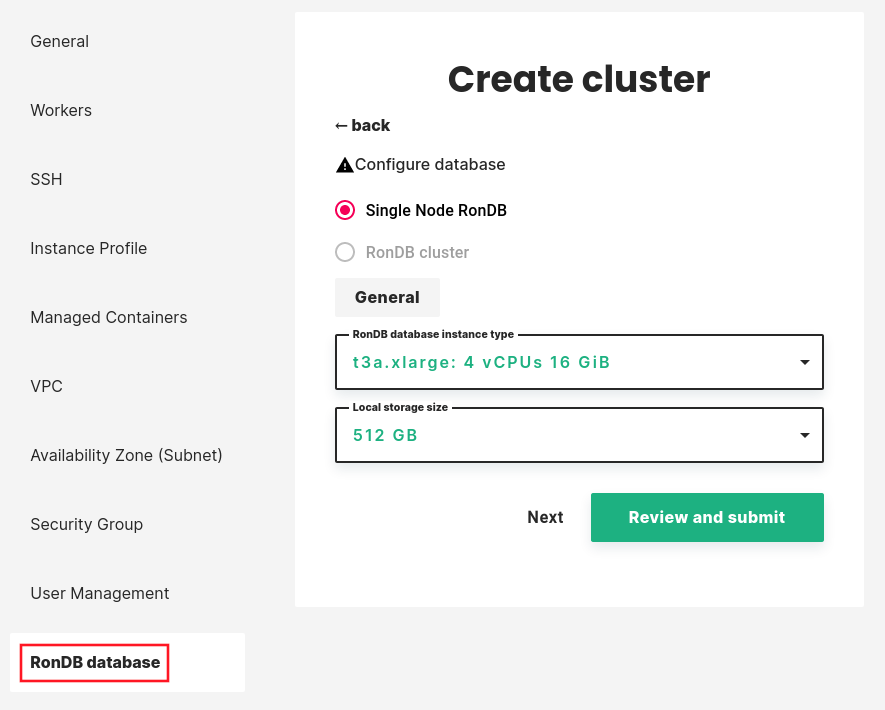
If you need to deploy a RonDB cluster instead of a single node please contact us.
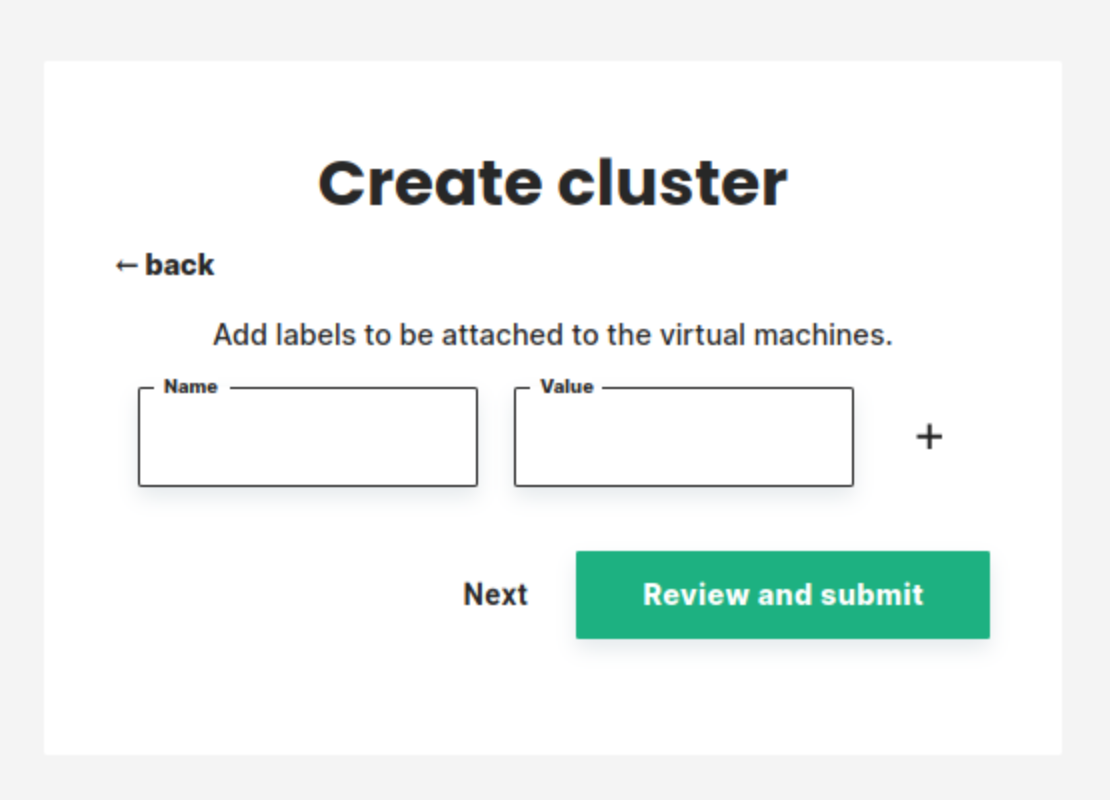
Step 10 add tags to your instances.#
In this step, you can define tags that will be added to the cluster virtual machines.
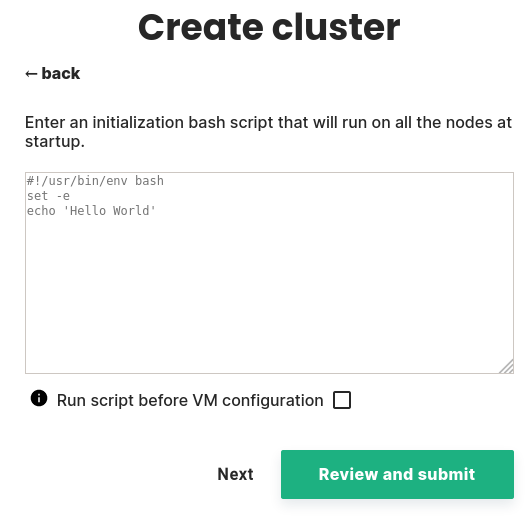
Step 10 add an init script to your instances.#
In this step, you can enter an initialization script that will be run at startup on every instance.
You can select whether this script will run before or after the VM configuration. Be cautious if you select to run it before the VM configuration as this might affect Cluster creation.
Note
this init script must be a bash script starting with #!/usr/bin/env bash
Step 12 Review and create#
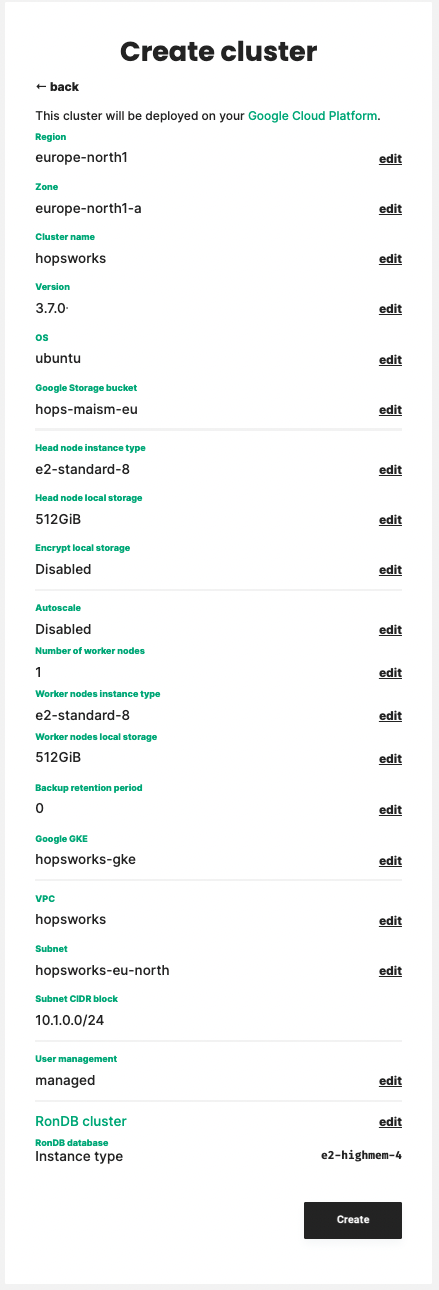
Review all information and select Create:
The cluster will start. This will take a few minutes:
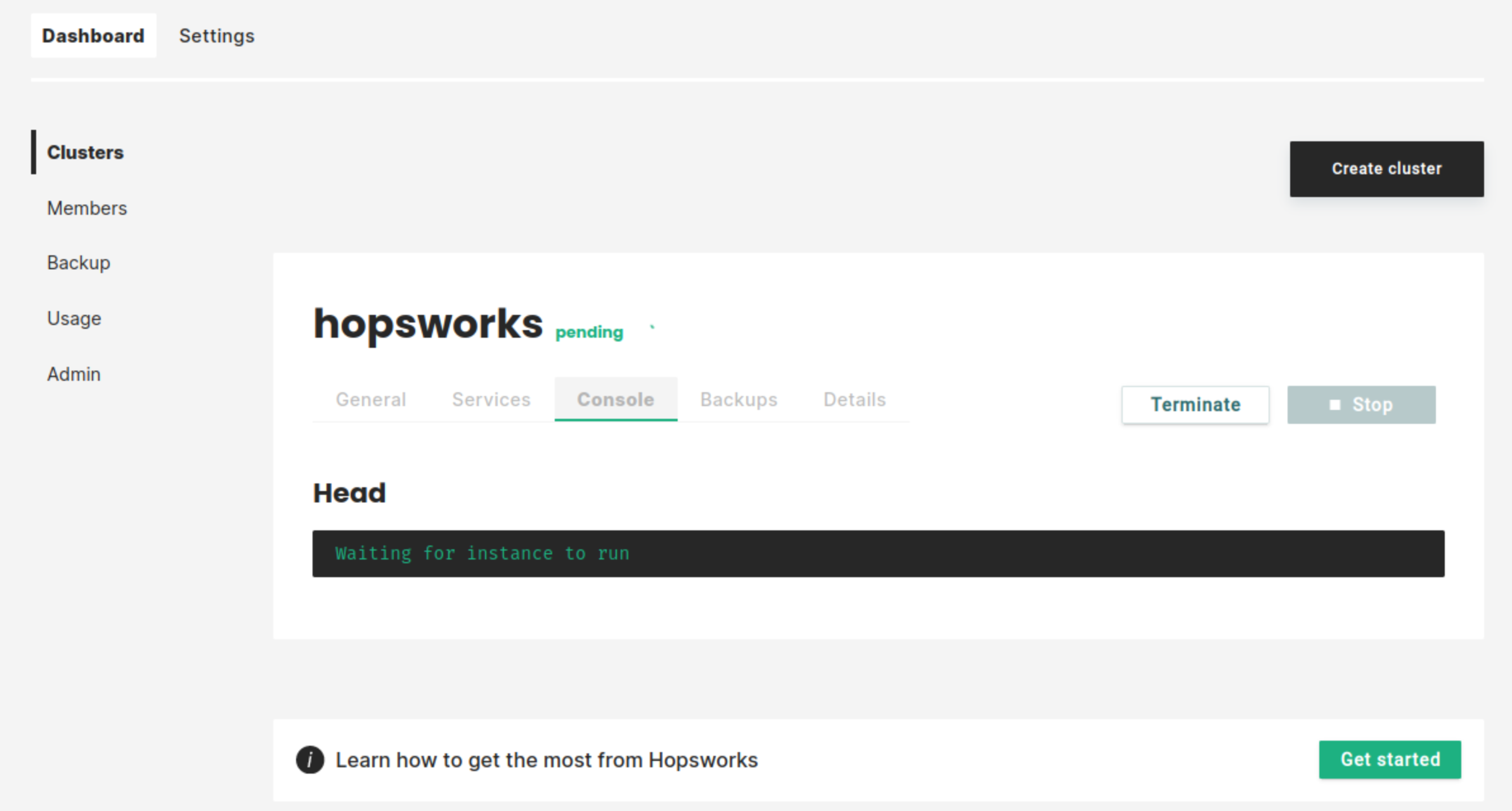
As soon as the cluster has started, you will be able to log in to your new Hopsworks cluster. You will also be able to stop, restart, or terminate the cluster.