Introduction#
Vector similarity search (also called similarity search) is a technique enabling the retrieval of similar items based on their vector embeddings or representations. Its applications range across various domains, from recommendation systems to image similarity and beyond. In Hopsworks, vector similarity search is enabled by extending an online feature group with approximate nearest neighbor search capabilities through a vector database, such as Opensearch. This guide provides a detailed walkthrough on how to leverage Hopsworks for vector similarity search.
Extending Feature Groups with Similarity Search#
In Hopsworks, each vector embedding in a feature group is stored in an index within the backing vector database. By default, vector embeddings are stored in the default index for the project (created for every project in Hopsworks), but you have the option to create a new index for a feature group if needed. Creating a separate index per feature group is particularly useful for large volumes of data, ensuring that when a feature group is deleted, its associated index is also removed. For feature groups that use the default project index, the index will only be removed when the project is deleted - not when the feature group is deleted. The index will store all the vector embeddings defined in that feature group, if you have more than one vector embedding in the feature group.
In the following example, we explicitly define an index for the feature group:
from hsfs import embedding
# Specify optionally the index in the vector database
emb = embedding.EmbeddingIndex(index_name="news_fg")
Then, add one or more embedding features to the index. Name and dimension of the embedding features are required for identifying which features should be indexed for k-nearest neighbor (KNN) search. In this example, we get the dimension of the embedding by taking the length of the value of the embedding_heading column in the first row of the dataframe df. Optionally, you can specify the similarity function among l2_norm, cosine, and dot_product.
# Add embedding feature to the index
emb.add_embedding("embedding_heading", len(df["embedding_heading"][0]))
Next, you create a feature group with the embedding_index and ingest data to the feature group. When the embedding_index is provided, the vector database is used as online feature store. That is, all the features in the feature group are stored exclusively in the vector database. The advantage of storing all features in the vector database is that it enables similarity search, and push-down filtering for all feature values.
# Create a feature group with the embedding index
news_fg = fs.get_or_create_feature_group(
name=f"news_fg",
embedding_index=emb, # Provide the embedding index created
primary_key=["news_id"],
version=version,
online_enabled=True
)
# Write a DataFrame to the feature group, including the offline store and the ANN index (in the Vector Database)
news_fg.insert(df)
Similarity Search for Feature Groups using Vector Embeddings#
You provide a vector embedding as a parameter to the search query using find_neighbors, and it returns the rows in the online feature group that have vector embedding values most similar to the provided vector embedding.
It is also possible to filter rows by specifying a filter on any of the features in the feature group. The filter is pushed down to the vector database to improve query performance.
In the first code snippet below, find_neighbors returns 3 rows in news_fg that have the closest news_description values to the provided news_description. In the second code snippet below, we only return news articles with a newstype of sports.
# Search neighbor embedding with k=3
news_fg.find_neighbors(model.encode(news_description), k=3)
# Filter and search
news_fg.find_neighbors(model.encode(news_description), k=3, filter=news_fg.newstype == "sports")
To analyze feature values at specific points in time, you can utilize time travel functionality:
# Time travel and read from the offline feature store
news_fg.as_of(time_in_past).read()
Querying Similar Embeddings with Additional features#
You can also use similarity search for vector embedding features in feature views. In the code snippet below, we create a feature view by selecting features from the earlier news_fg and a new feature group view_fg. If you include a feature group with vector embedding features in a feature view, whether or not the vector embedding features are selected, you can call find_neighbors on the feature view, and it will return rows containing all the feature values in the feature view. In the example below, a list of heading and view_cnt will be returned for the news articles which are closet to provided news_description.
view_fg = fs.get_or_create_feature_group(
name="view_fg",
primary_key=["news_id"],
version=version,
online_enabled=True
)
fv = fs.get_or_create_feature_view(
"news_view", version=version,
query=news_fg.select(["heading"]).join(view_fg.select(["view_cnt"]))
)
fv.find_neighbors(model.encode(news_description), k=5)
Note that you can use similarity search from the feature view only if the feature group which you are querying with find_neighbors has all the primary keys of the other feature groups. In the example above, you are querying against the feature group news_fg which has the vector embedding features, and it has the feature "news_id" which is the primary key of the feature group view_fg. But if page_fg is used as illustrated below, find_neighbors will fail to return any features because primary key page_id does not exist in news_fg.
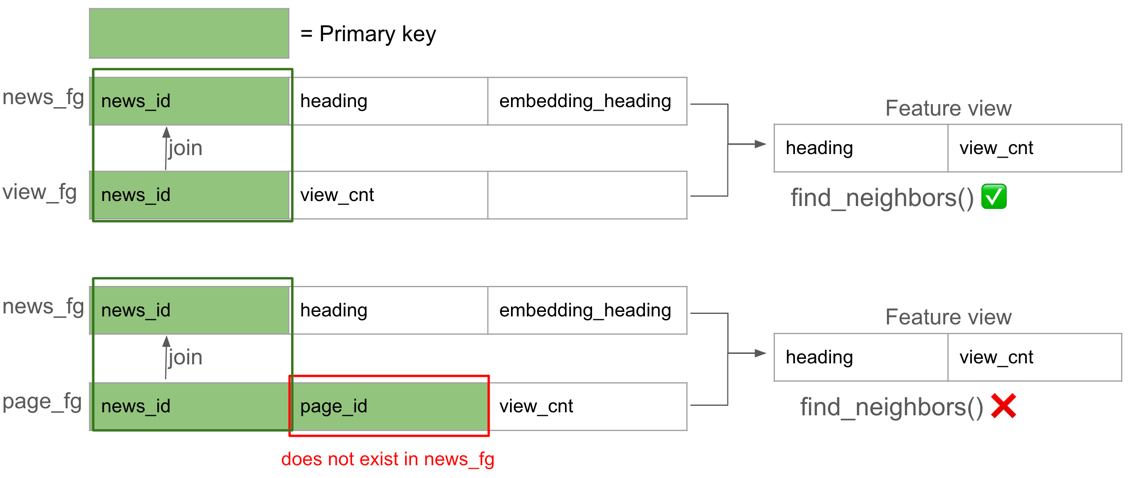
It is also possible to get back feature vector by providing the primary keys, but it is not recommended as explained in the next section. The client fetches feature vector from the vector store and the online store for news_fg and view_fg respectively.
fv.get_feature_vector({"news_id": 1})
Performance considerations for Feature Groups with Embeddings#
Choose Features for Vector Store#
While it is possible to update feature value in vector store, updating feature value in online store is more efficient. If you have features which are frequently being updated and do not require for filtering, consider storing them separately in a different feature group. As shown in the previous example, view_cnt is updated frequently and stored separately. You can then get all the required features by using feature view.
Choose the Appropriate Online Feature Stores#
There are 2 types of online feature stores in Hopsworks: online store (RonDB) and vector store (Opensearch). Online store is designed for retrieving feature vectors efficiently with low latency. Vector store is designed for finding similar embedding efficiently. If similarity search is not required, using online store is recommended for low latency retrieval of feature values including embedding.
Use New Index per Feature Group#
Create a new index per feature group to optimize retrieval performance.
Next step#
Explore the news search example, demonstrating how to use Hopsworks for implementing a news search application using natural language in the application. Additionally, you can see the application of querying similar embeddings with additional features in this news rank example.