How To Schedule a Job#
Introduction#
Hopsworks clusters can run jobs on a schedule, allowing you to automate the execution. Whether you need to backfill your feature groups on a nightly basis or run a model training pipeline every week, the Hopsworks scheduler will help you automate these tasks. Each job can be configured to have a single schedule. For more advanced use cases, Hopsworks integrates with any DAG manager and directly with the open-source Apache Airflow, check out our Airflow Guide.
Schedules can be defined using the drop down menus in the UI or a Quartz cron expression.
Schedule frequency
The Hopsworks scheduler runs every minute. As such, the scheduling frequency should be of at least 1 minute.
Parallel executions
If a job execution needs to be scheduled, the scheduler will first check that there are no active executions for that job. If there is an execution running, the scheduler will postpone the execution until the running one is done.
UI#
Scheduling Jobs#
You can define a schedule for a job during the creation of the job itself or after the job has been created from the job overview UI.
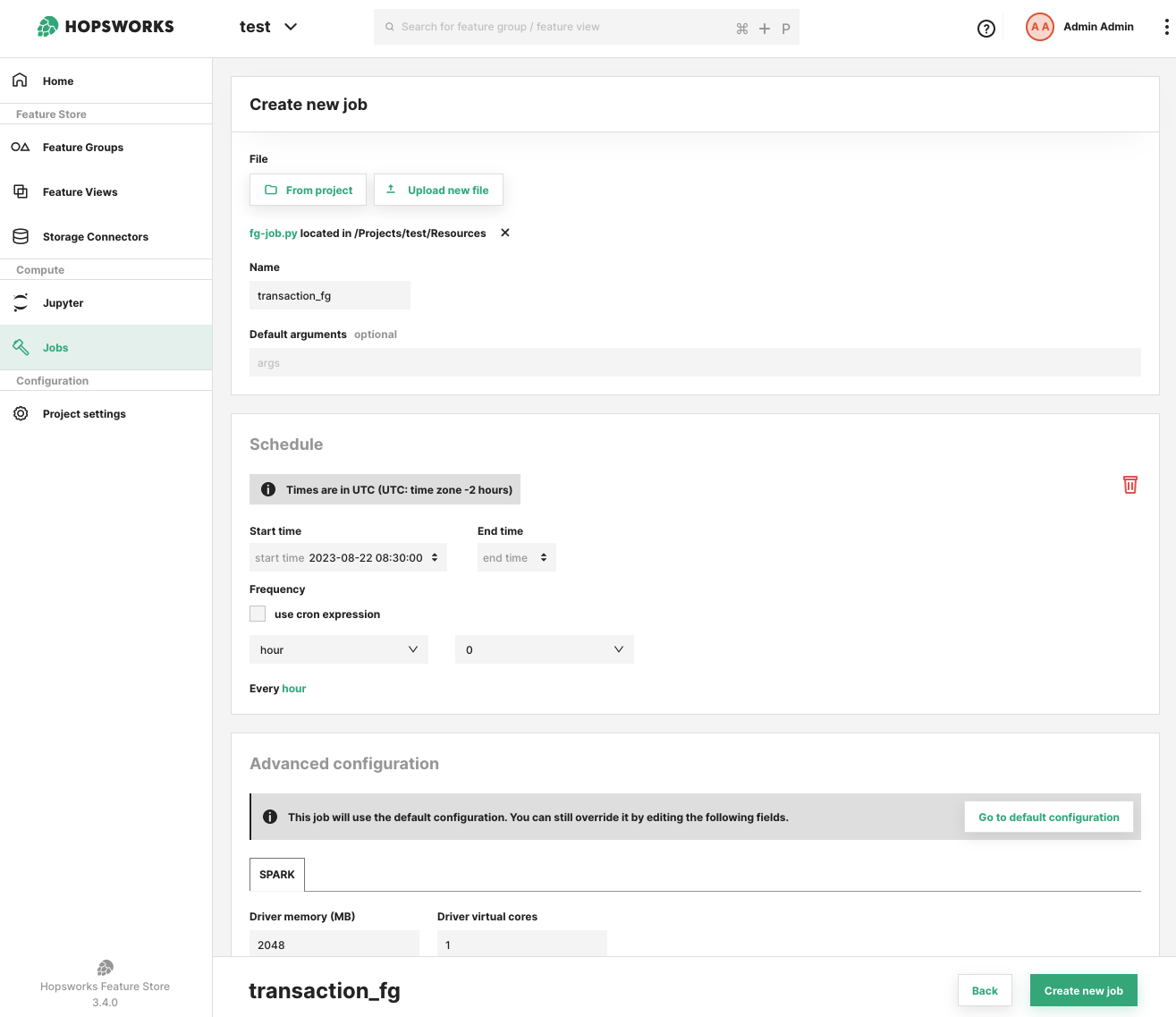
The add schedule prompt requires you to select a frequency either through the drop down menus or by using a cron expression. You can also provide a start time to specify from when the schedule should have effect. The start time can also be in the past. If that's the case, the scheduler will backfill the executions from the specified start time. As mentioned above, the execution backfilling will happen one execution at the time.
You can optionally provide an end date time to specify until when the scheduling should continue. The end time can also be in the past.
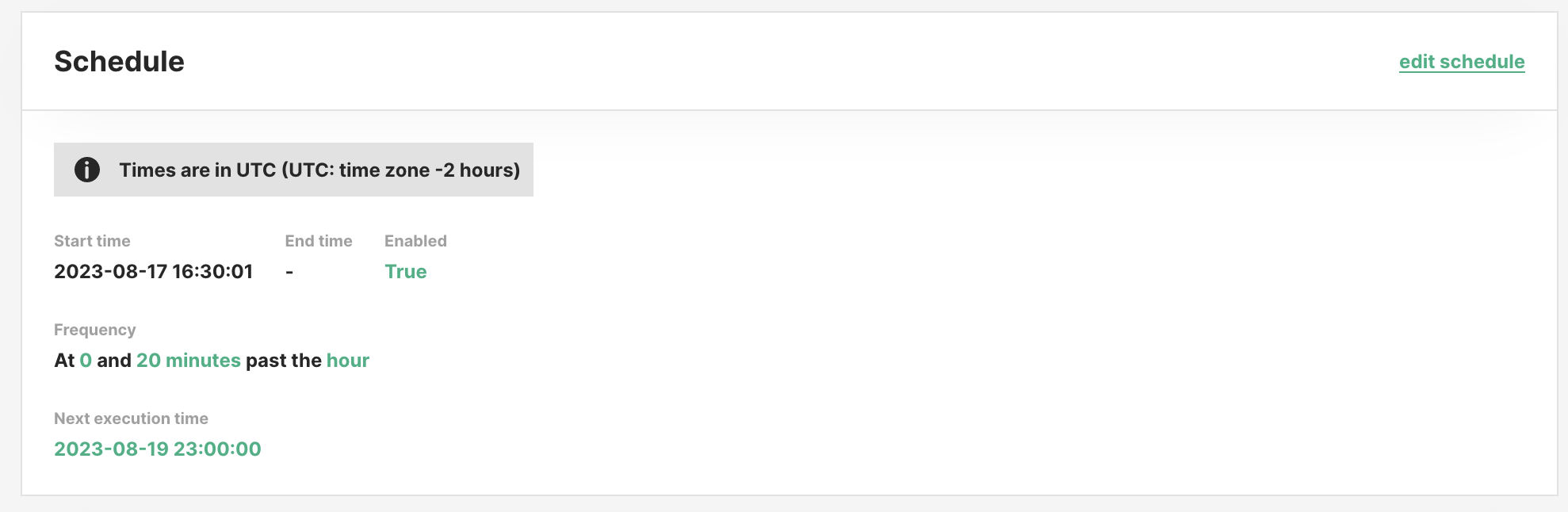
In the job overview, you can see the current scheduling configuration, whether or not it is enabled and when the next execution is planned for.
All times will be considered as UTC time.
Job argument#
When a job execution is triggered by the scheduler, a -start_time argument is added to the job arguments. The -start_time value will be the time of the scheduled execution in UTC in the ISO-8601 format (e.g.: -start_time 2023-08-19T18:00:00Z).
The -start_time value passed as argument represents the time when the execution was scheduled, not when the execution was started. For example, if the scheduled execution time was in the past (e.g. in the case of backfilling), the -start_time passed to the execution is the time in the past, not the current time when the execution is running. Similarly, if the scheduler was not running for a period of time, when it comes back online, it will start the executions it missed to schedule while offline. Even in that case, the -start_time value will contain the time at which the execution was supposed to be started, not the current time.
Disable / Enable a schedule#
You can decide to pause the scheduling of a job and avoid new executions to be started. You can later on re-enable the same scheduling configuration, and the scheduler will run the executions that were skipped while the schedule was disabled, if any, sequentially. In this way you will backfill the executions in between.
You can skip the backfilling of the executions by editing the scheduling configuration and bringing forward the schedule start time for the job.
Delete a scheduling#
You can remove the schedule for a job using the UI and by clicking on the trash icon on the schedule section of the job overview. If you re-schedule a job after having deleted the previous schedule, even with the same options, it will not take into account previous scheduled executions.