ArrowFlight Server with DuckDB#
By default, Hopsworks uses big data technologies (Spark or Hive) to create training data and read data for Python clients. This is great for large datasets, but for small or moderately sized datasets (think of the size of data that would fit in a Pandas DataFrame in your local Python environment), the overhead of starting a Spark or Hive job and doing distributed data processing can be significant.
ArrowFlight Server with DuckDB significantly reduces the time that Python clients need to read feature groups and batch inference data from the Feature Store, as well as creating moderately-sized in-memory training datasets.
When the service is enabled, clients will automatically use it for the following operations:
- reading Feature Groups
- reading Queries
- reading Training Datasets
- creating In-Memory Training Datasets
- reading Batch Inference Data For larger datasets, clients can still make use of the Spark/Hive backend by explicitly setting
read_options={"use_hive": True}.
Service configuration#
Note
Supported only on AWS at the moment.
The ArrowFlight Server is co-located with RonDB in the Hopsworks cluster. If the ArrowFlight Server is activated, RonDB and ArrowFlight Server can each use up to 50% of the available resources on the node, so they can co-exist without impacting each other. Just like RonDB, the ArrowFlight Server can be replicated across multiple nodes to serve more clients at lower latency. To guarantee high performance, each individual ArrowFlight Server instance processes client requests sequentially. Requests will be queued for up to 10 minutes before they are rejected.
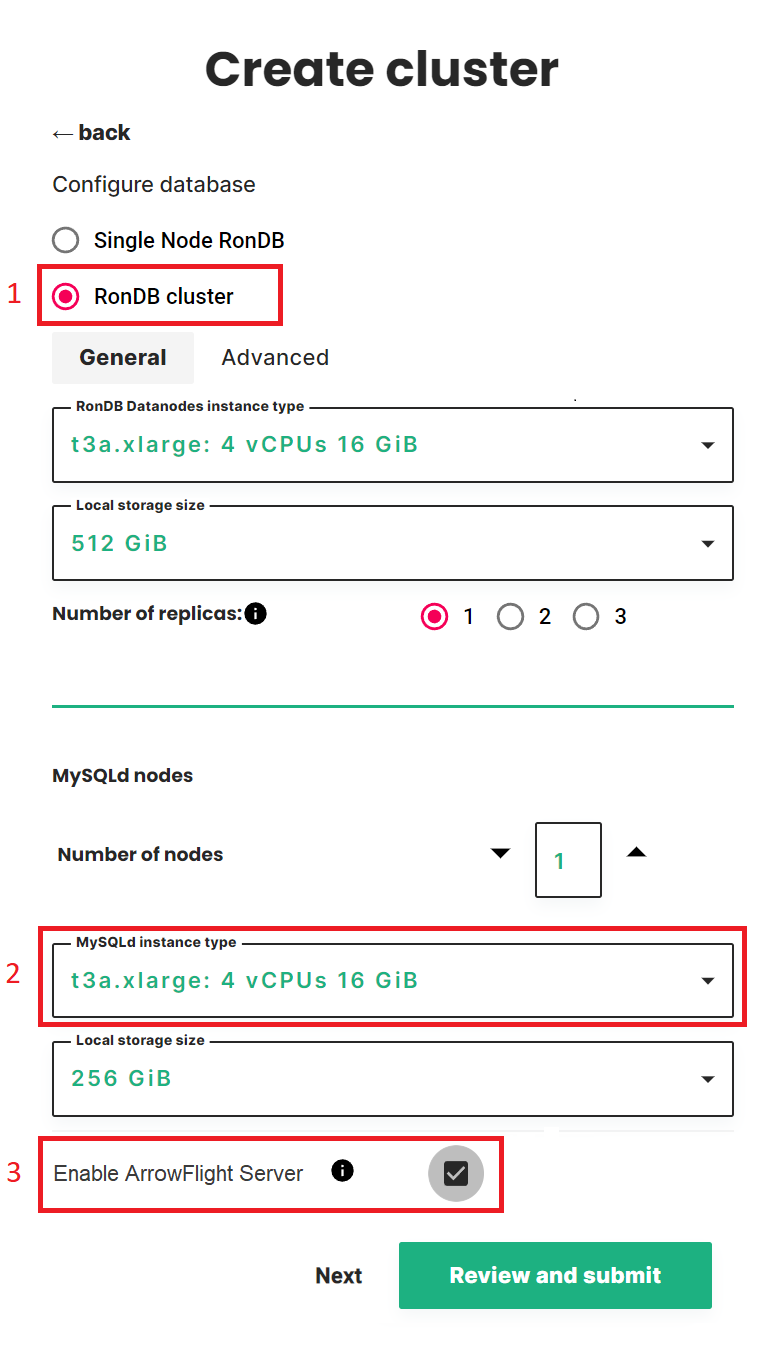
To deploy ArrowFlight Server on a cluster:
- Select "RonDB cluster"
- Select an instance type with at least 16GB of memory and 4 cores. (*)
- Tick the checkbox
Enable ArrowFlight Server.
(*) The service should have at least the 2x the amount of memory available that a typical Python client would have. Because RonDB and ArrowFlight Server share the same node we recommend selecting an instance type with at least 4x the client memory. For example, if the service serves Python clients with typically 4GB of memory, an instance with at least 16GB of memory should be selected. An instance with 16GB of memory will be able to read feature groups and training datasets of up to 10-100M rows, depending on the number of columns and size of the features (~2GB in parquet). The same instance will be able to create point-in-time correct training datasets with 1-10M rows, also depending on the number and the size of the features. Larger instances are able to handle larger datasets. The numbers scale roughly linearly with the instance size.