How To Run A Jupyter Notebook Job#
Introduction#
This guide describes how to configure a job to execute a Jupyter Notebook (.ipynb) and visualize the evaluated notebook.
All members of a project in Hopsworks can launch the following types of applications through a project's Jobs service:
- Python
- Apache Spark
- Ray
Launching a job of any type is very similar process, what mostly differs between job types is the various configuration parameters each job type comes with. Hopsworks support scheduling jobs to run on a regular basis, e.g backfilling a Feature Group by running your feature engineering pipeline nightly. Scheduling can be done both through the UI and the python API, checkout our Scheduling guide.
UI#
Step 1: Jobs overview#
The image below shows the Jobs overview page in Hopsworks and is accessed by clicking Jobs in the sidebar.
Step 2: Create new job dialog#
Click New Job and the following dialog will appear.
Step 3: Set the job type#
By default, the dialog will create a Spark job. To instead configure a Jupyter Notebook job, select PYTHON.
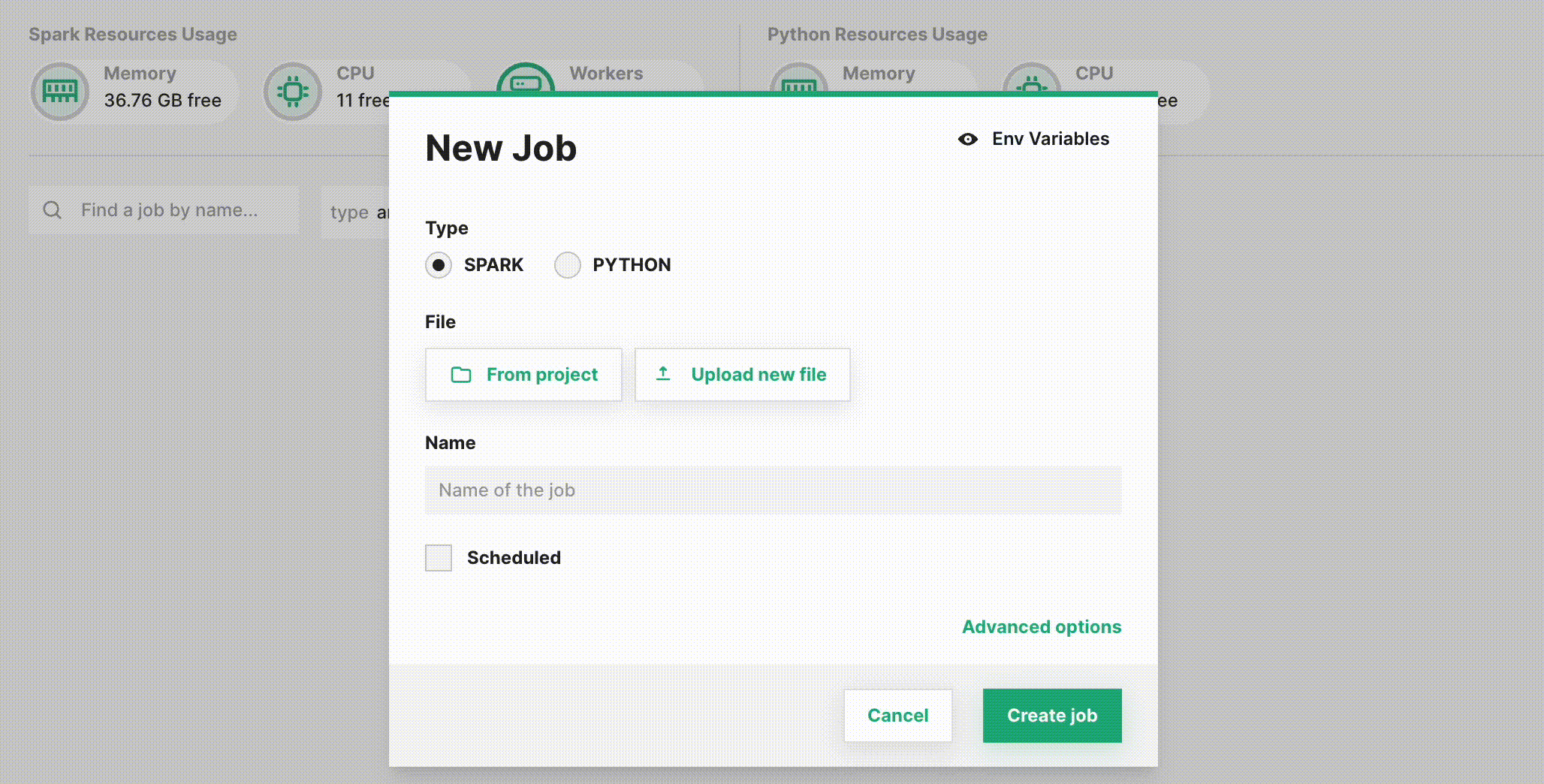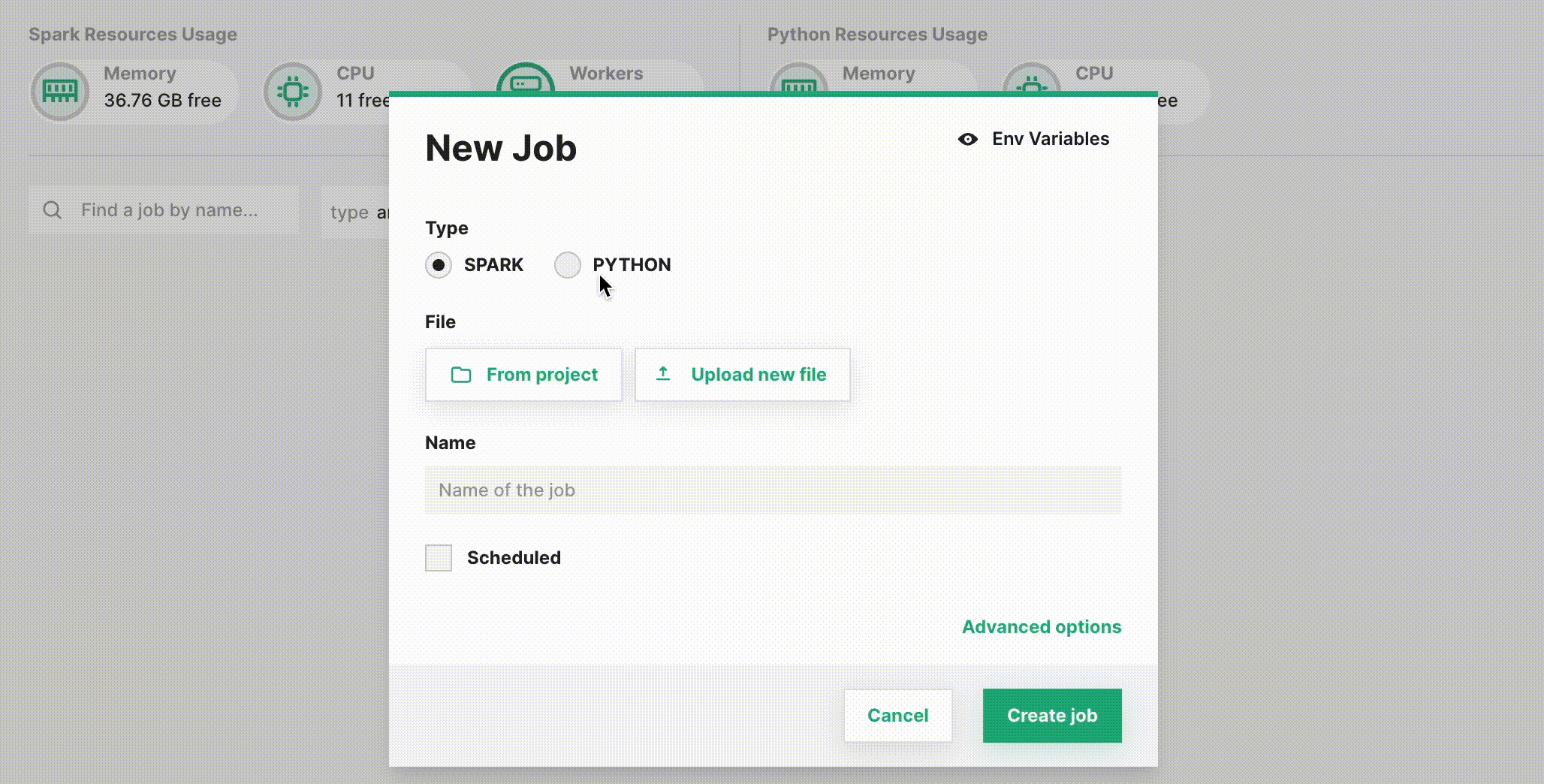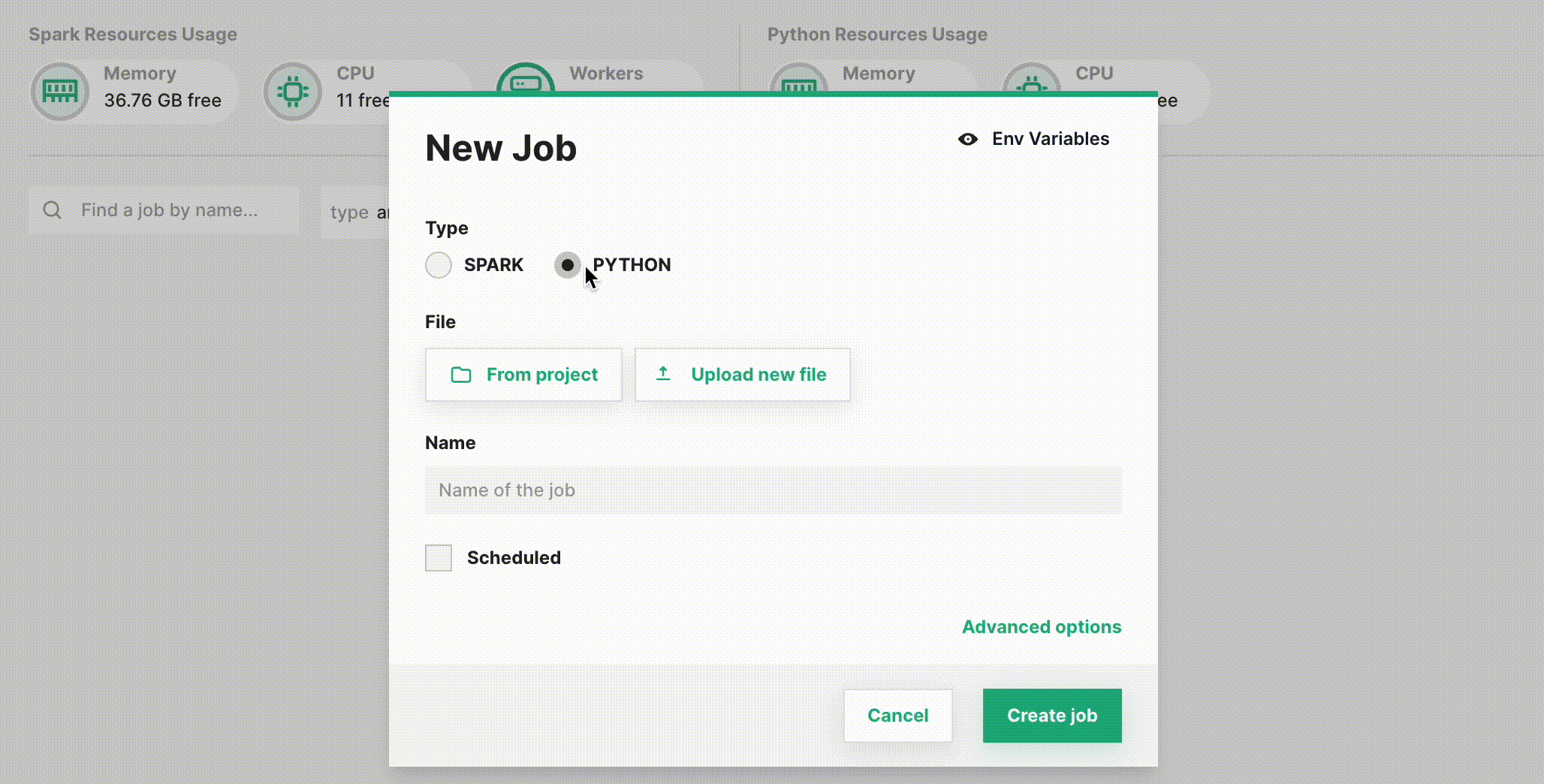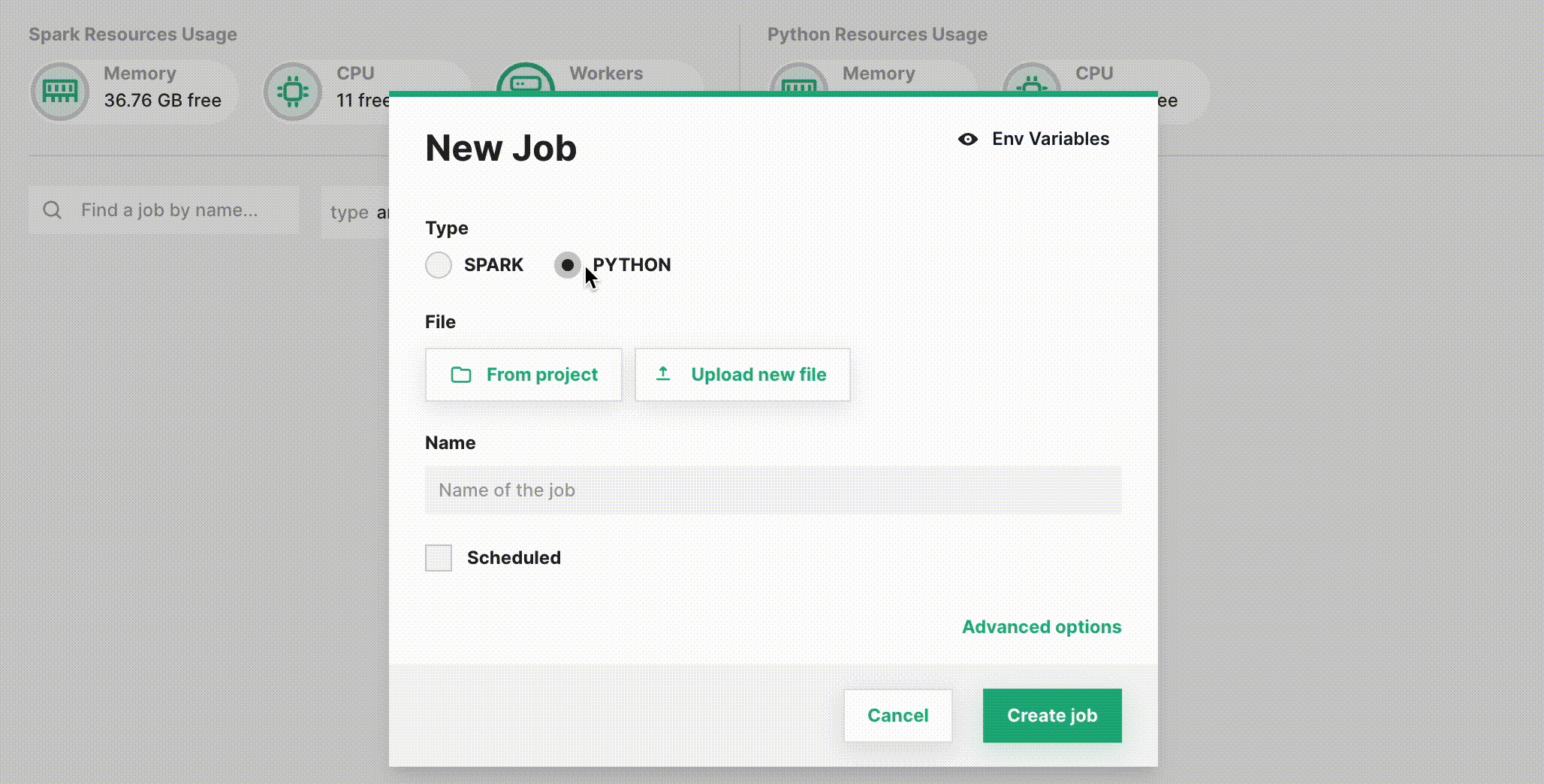
Step 4: Set the notebook#
Next step is to select the Jupyter Notebook to run. You can either select From project, if the file was previously uploaded to Hopsworks, or Upload new file which lets you select a file from your local filesystem as demonstrated below. By default, the job name is the same as the file name, but you can customize it as shown.
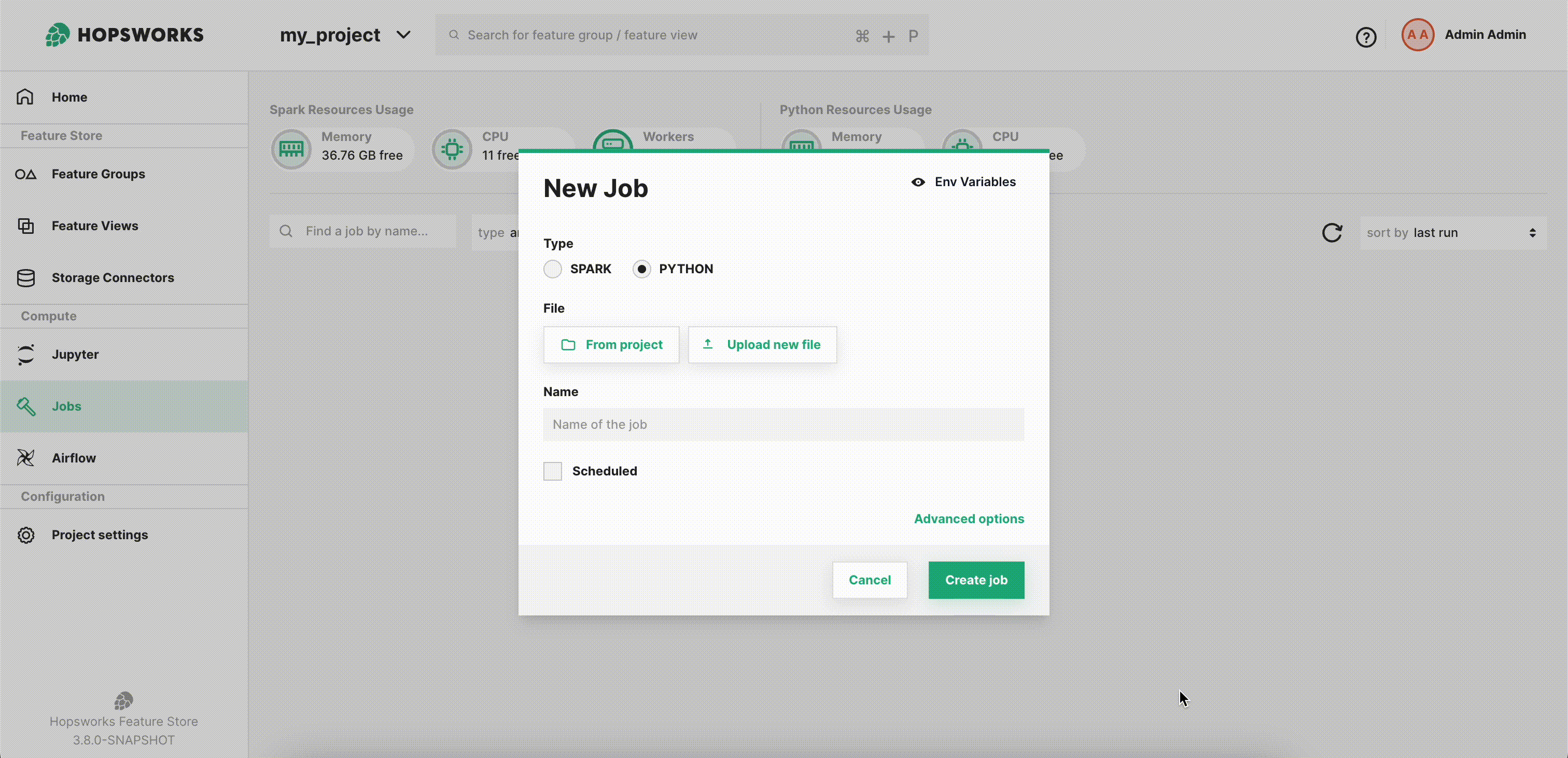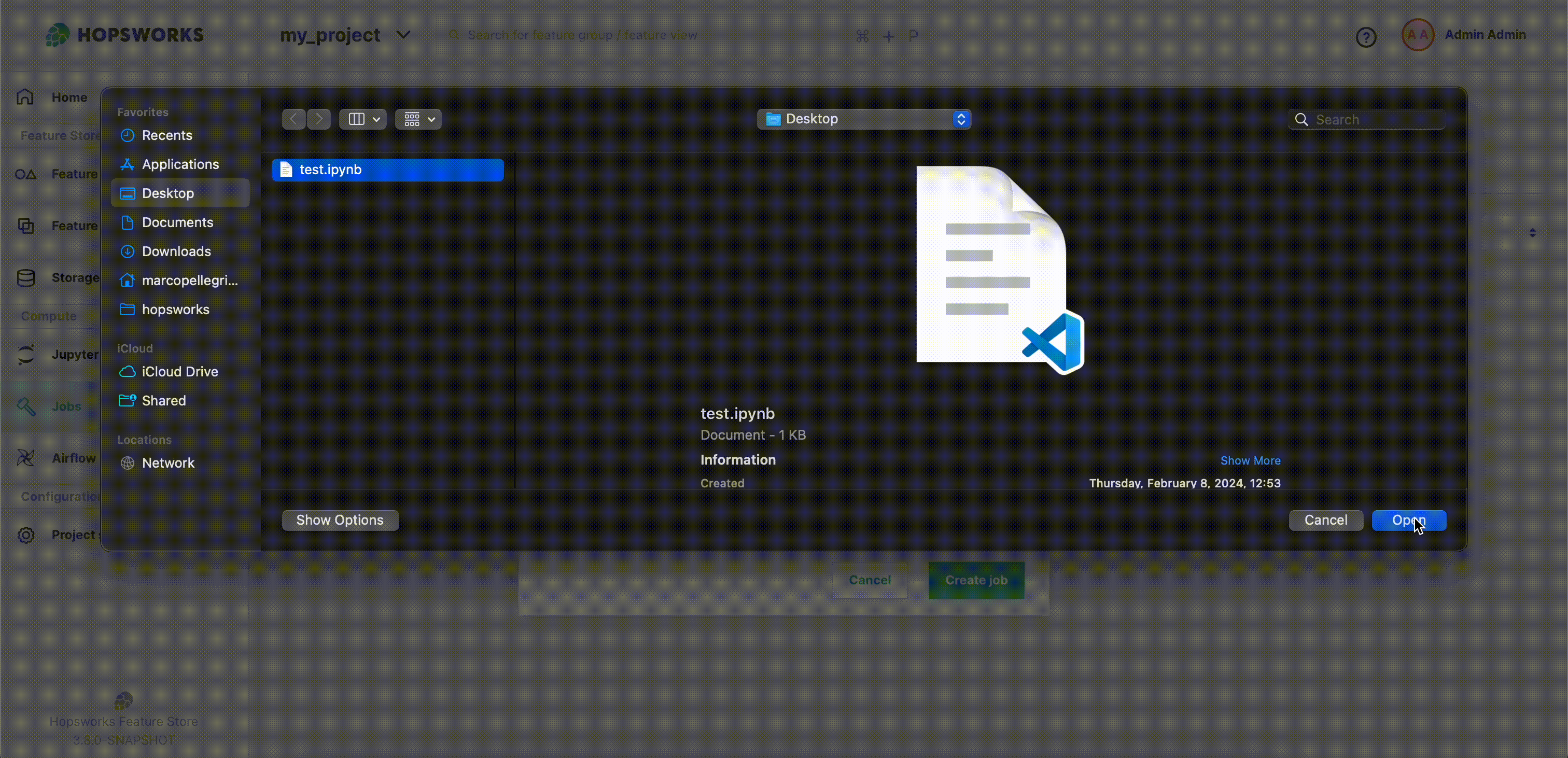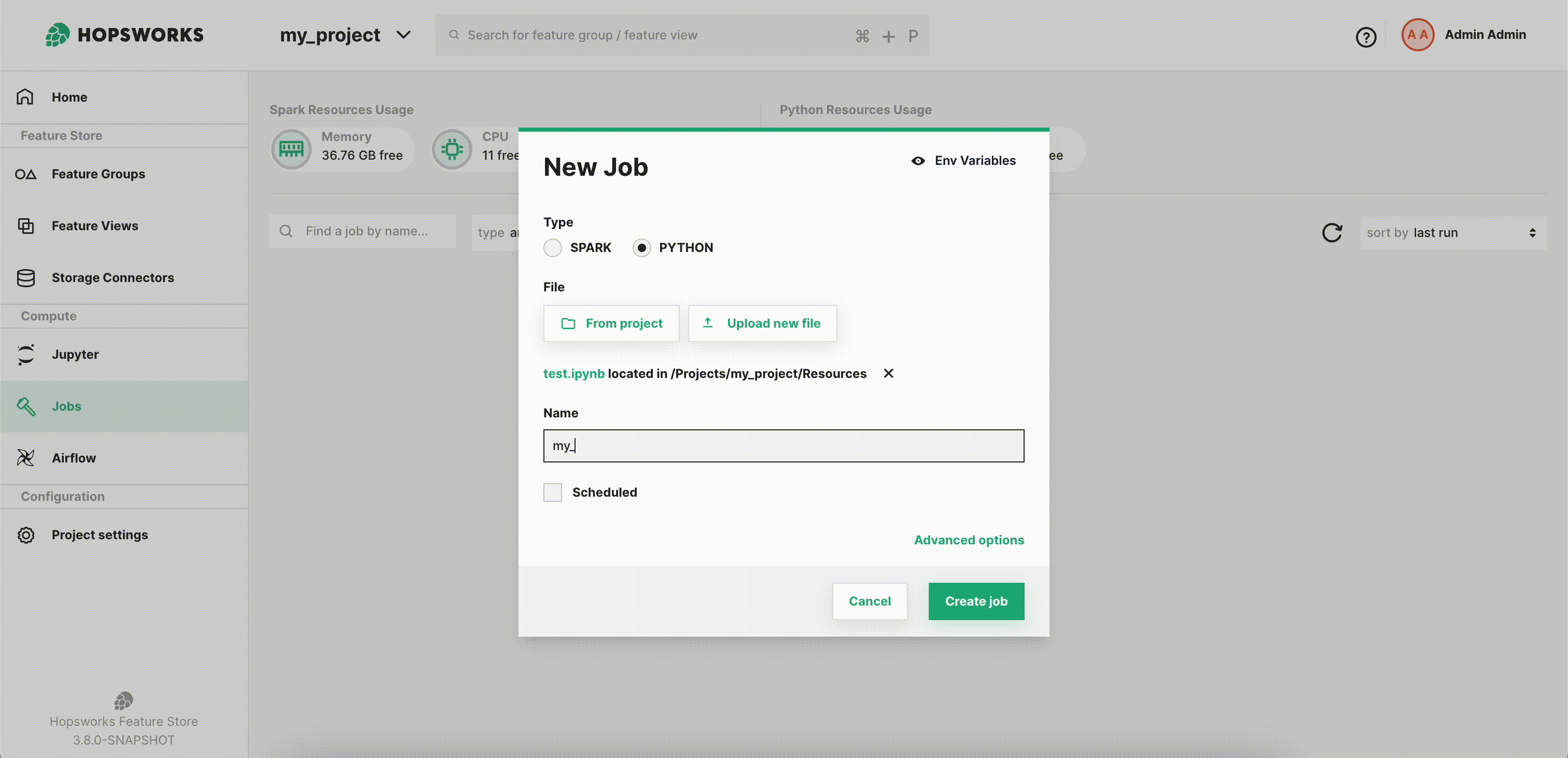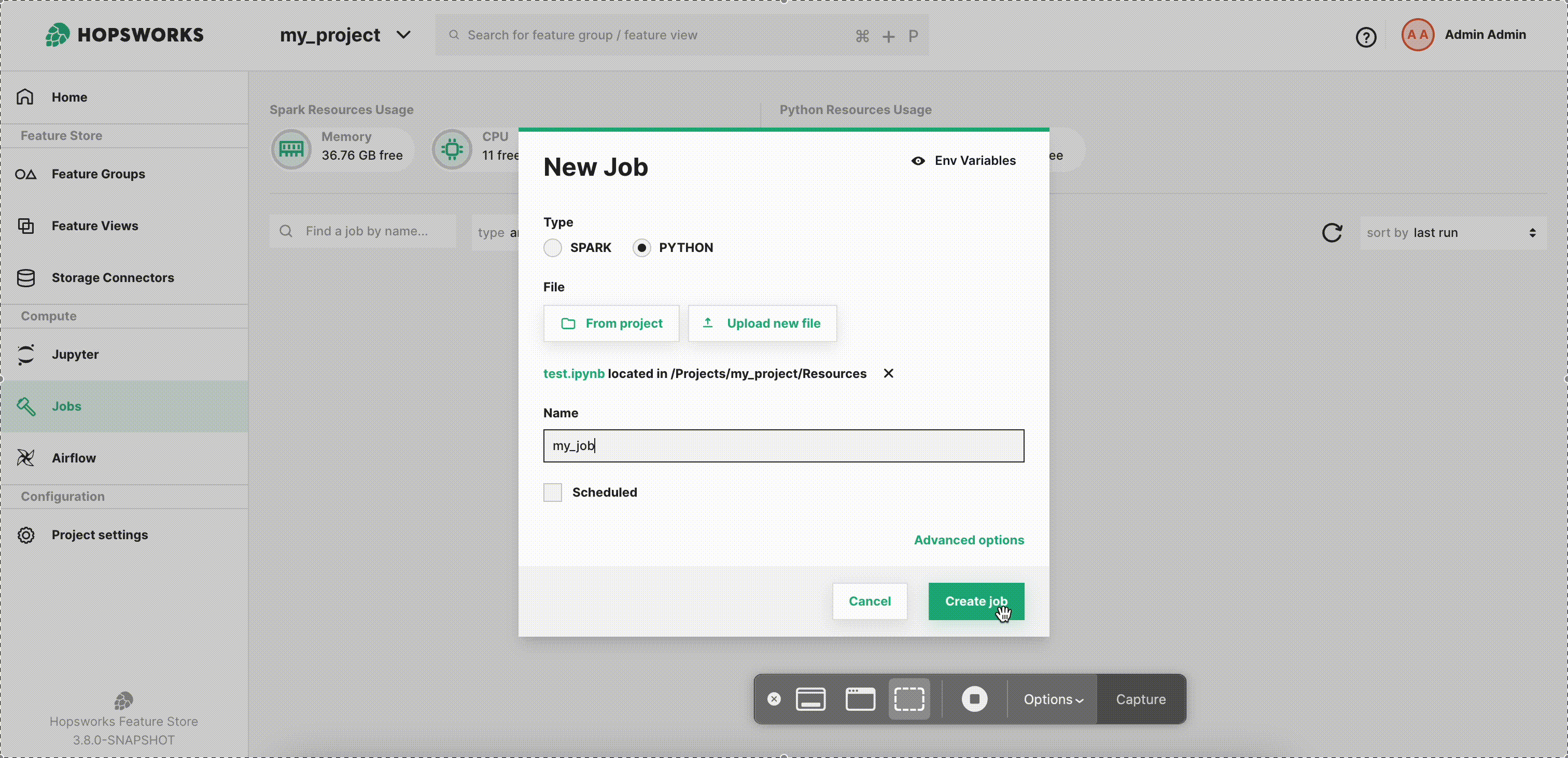
Then click Create job to create the job.
Step 5 (optional): Set the Jupyter Notebook arguments#
In the job settings, you can specify arguments for your notebook script. Arguments must be in the format of -p arg1 value1 -p arg2 value2. For each argument, you must first provide -p, followed by the parameter name (e.g. arg1), followed by its value (e.g. value1). The next step is to read the arguments in the notebook which is explained in this guide.
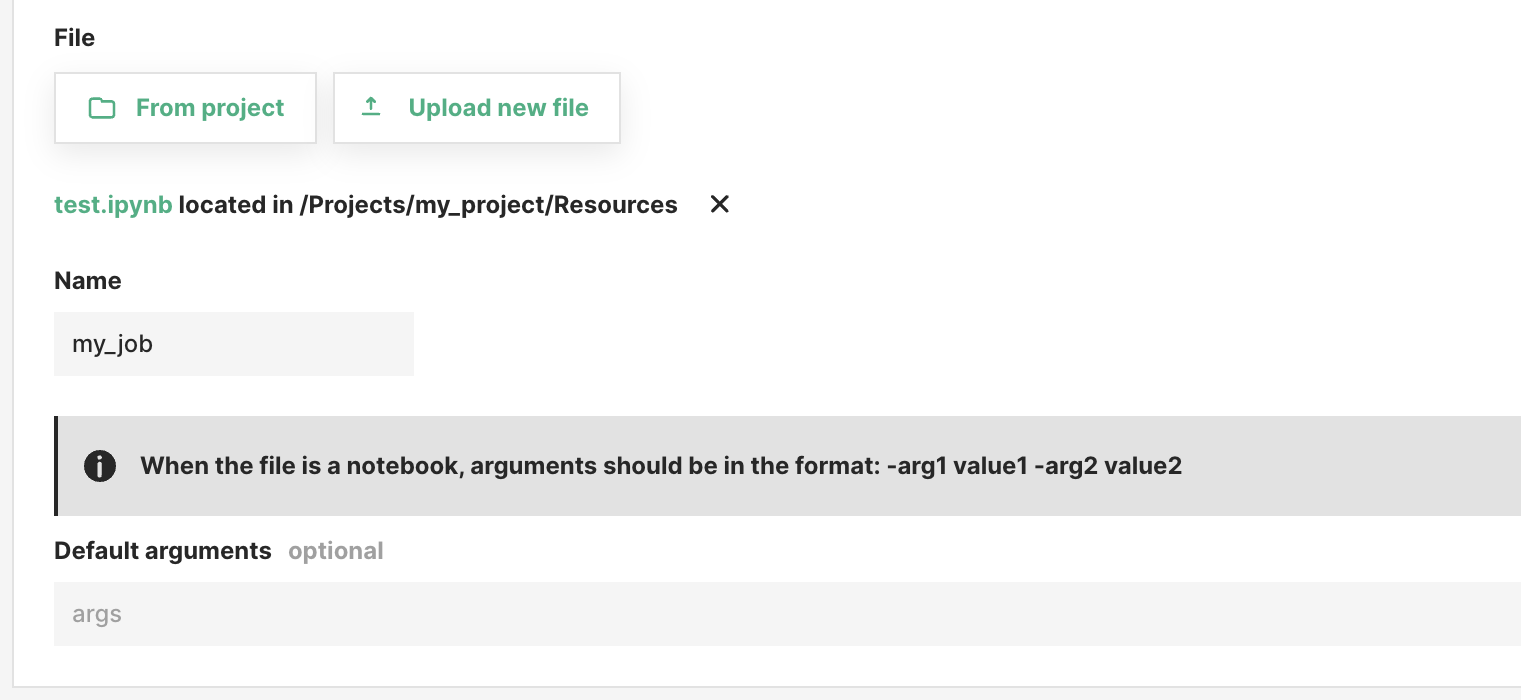
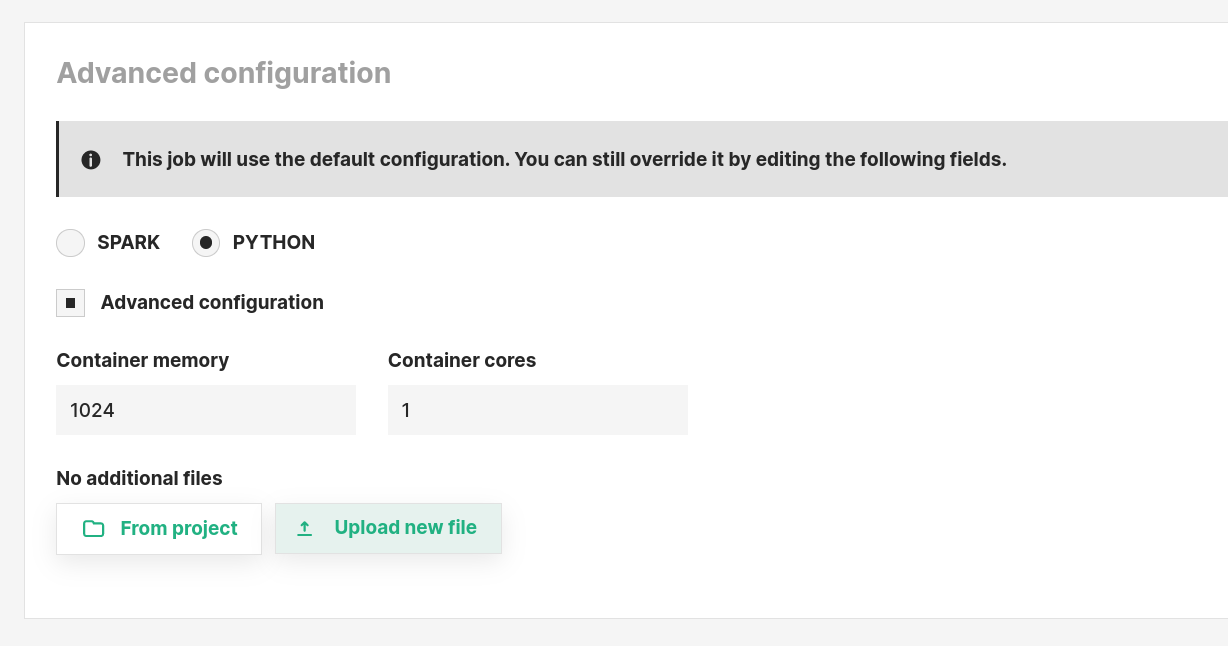
Step 6 (optional): Additional configuration#
It is possible to also set following configuration settings for a PYTHON job.
Environment: The python environment to useContainer memory: The amount of memory in MB to be allocated to the Jupyter Notebook scriptContainer cores: The number of cores to be allocated for the Jupyter Notebook scriptAdditional files: List of files that will be locally accessible in the working directory of the application. Only recommended to use if project datasets are not mounted under/hopsfs. You can always modify the arguments in the job settings.
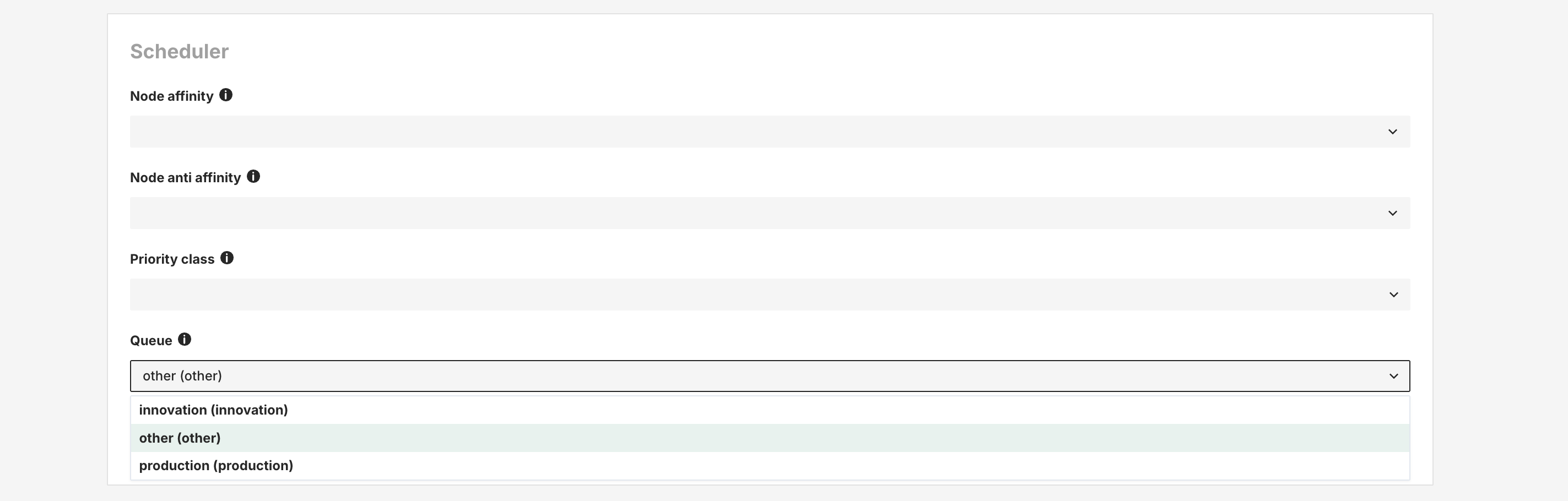
Step 7: (Kueue enabled) Select a Queue#
If the cluster is installed with Kueue enabled, you will need to select a queue in which the job should run. This can be done from Advance configuration -> Scheduler section.
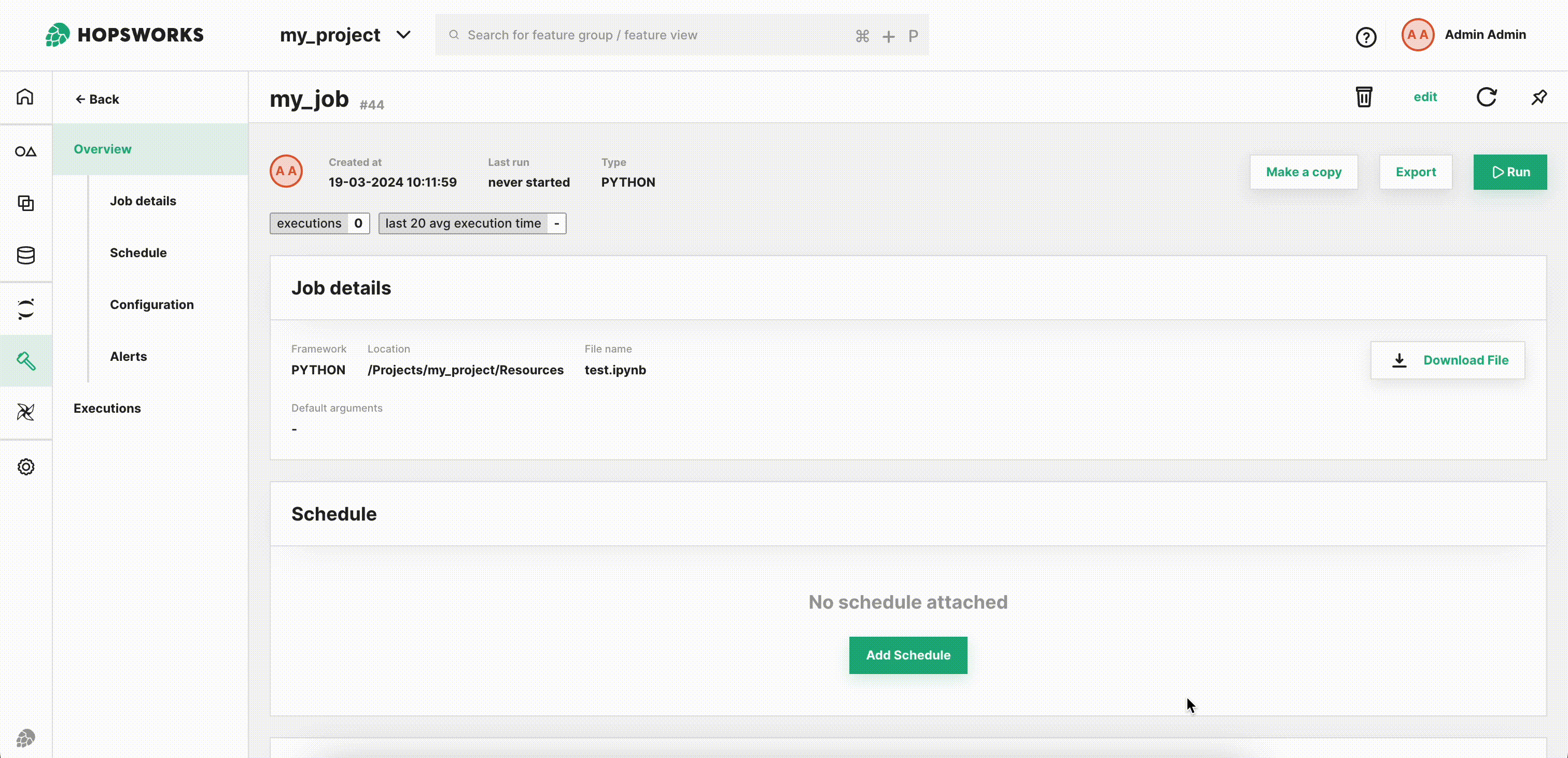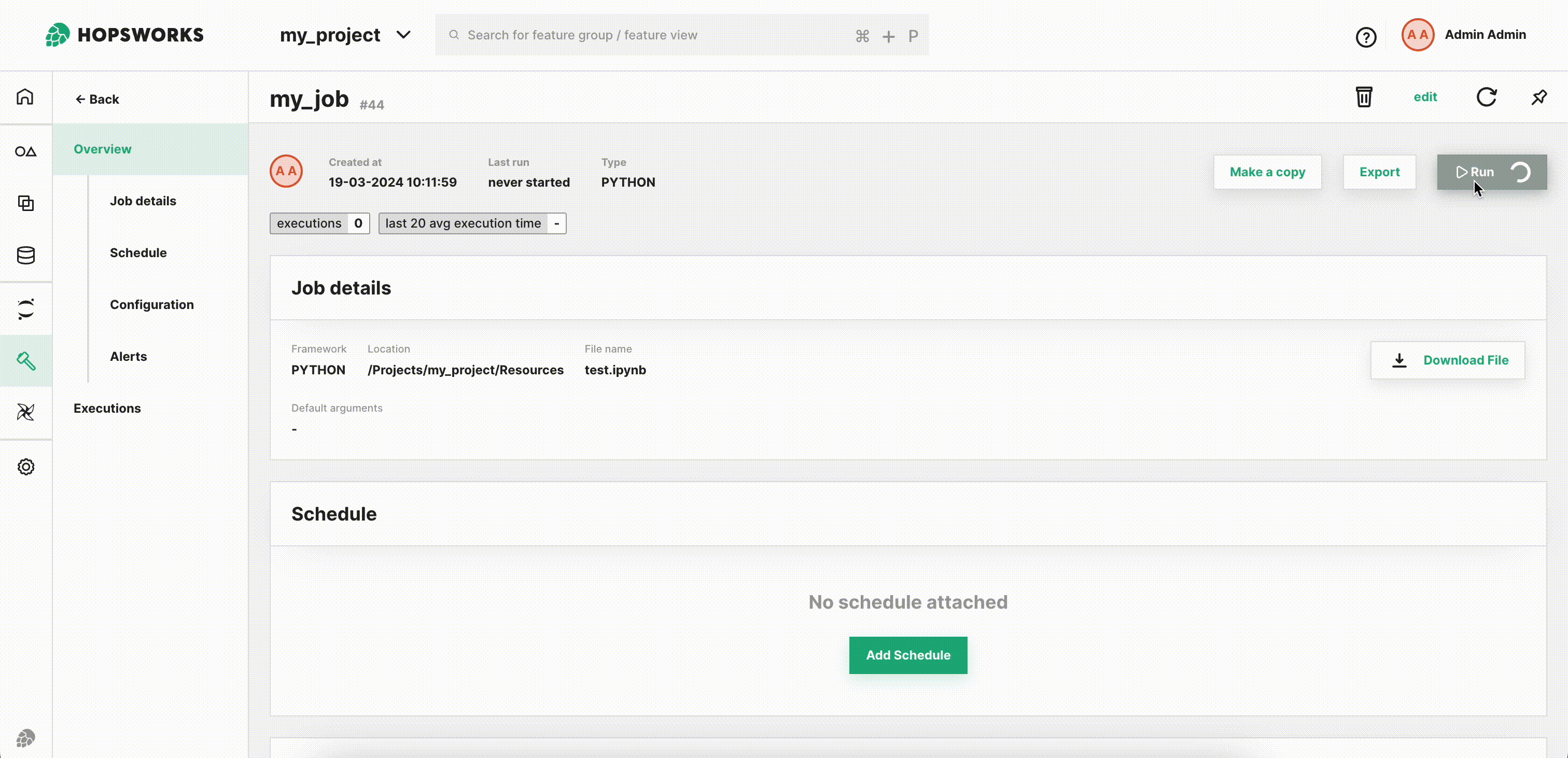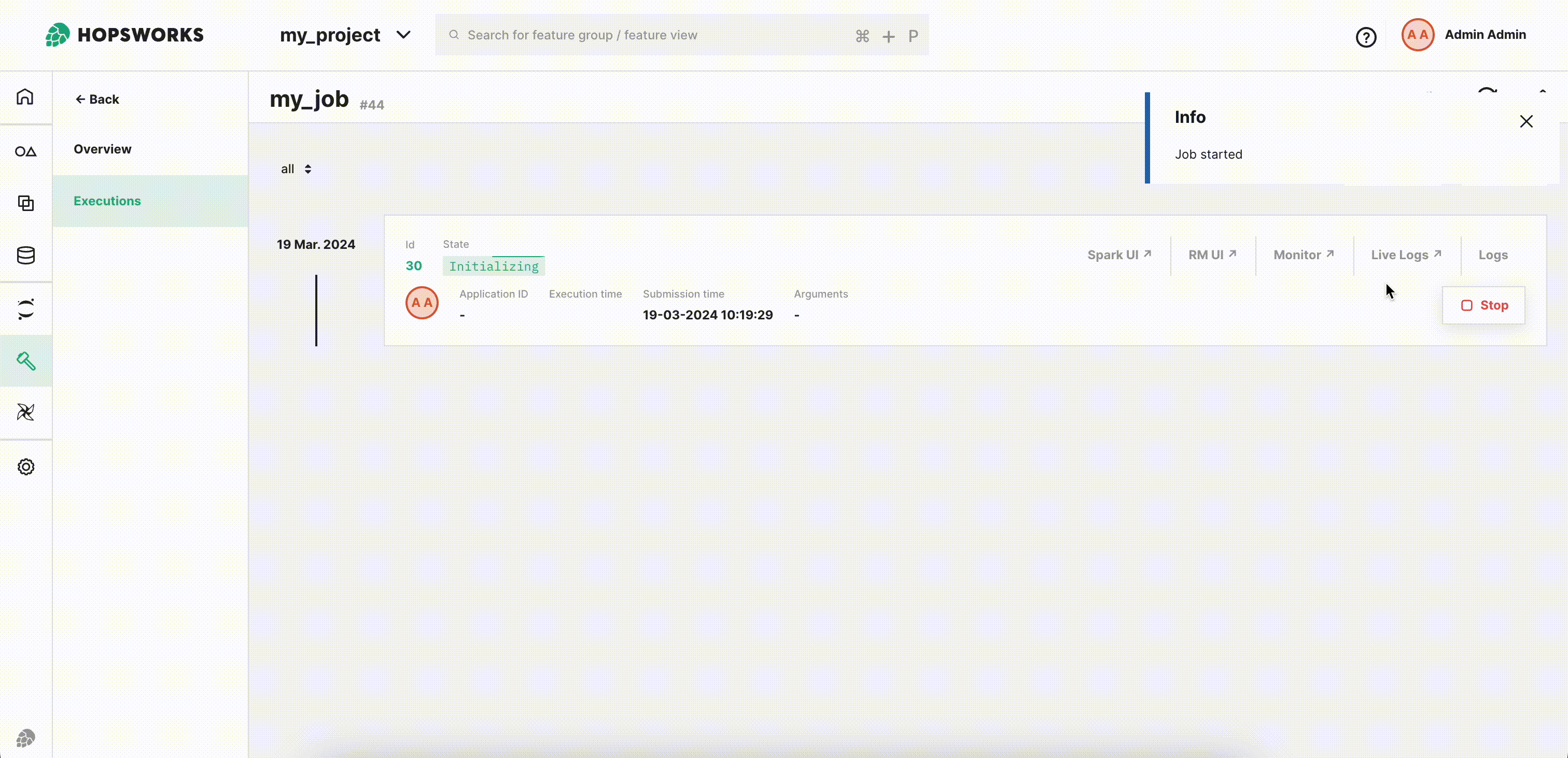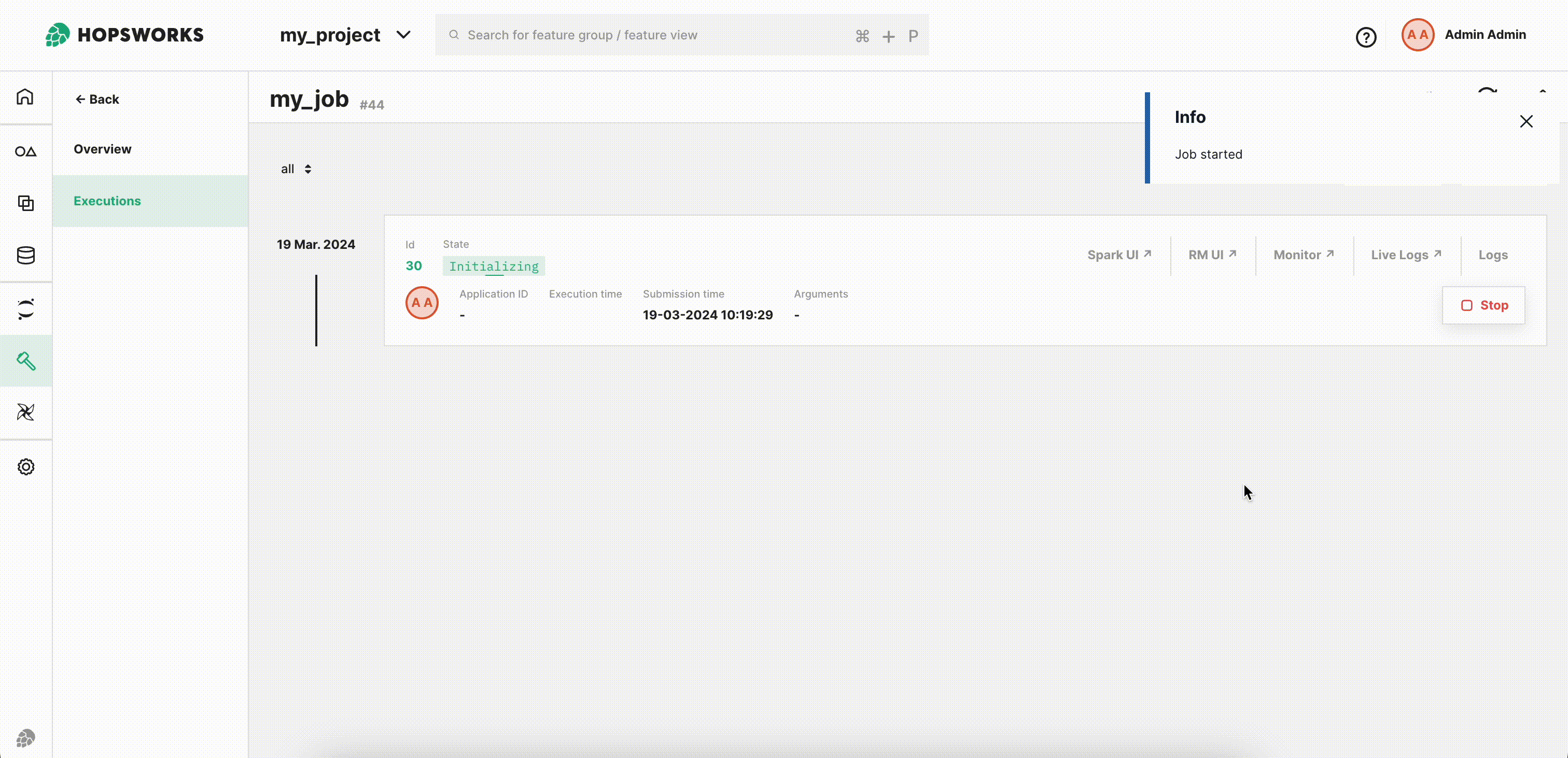
Step 8: Execute the job#
Now click the Run button to start the execution of the job. You will be redirected to the Executions page where you can see the list of all executions.
Step 9: Visualize output notebook#
Once the execution is finished, click Logs and then notebook out to see the logs for the execution.
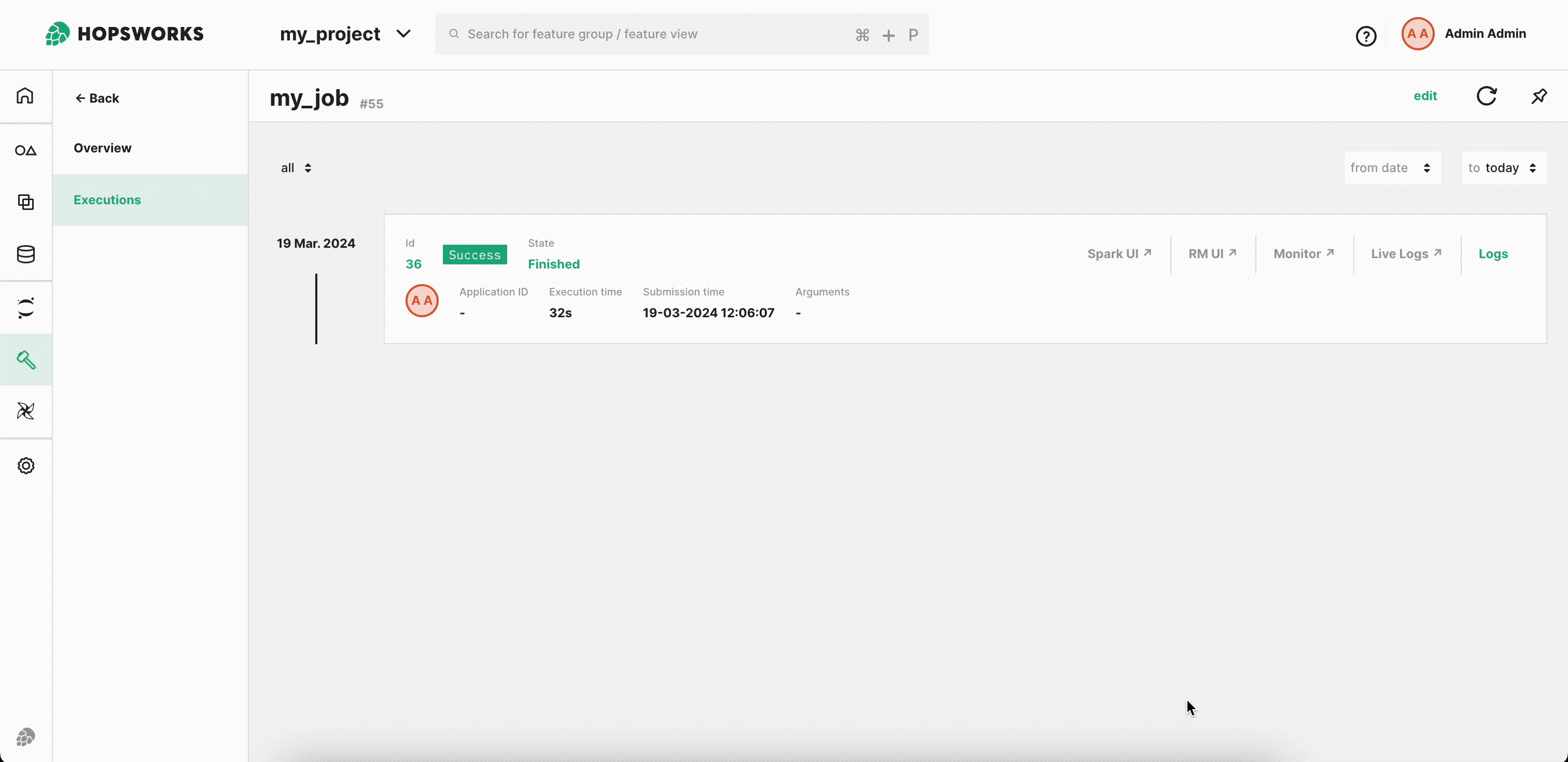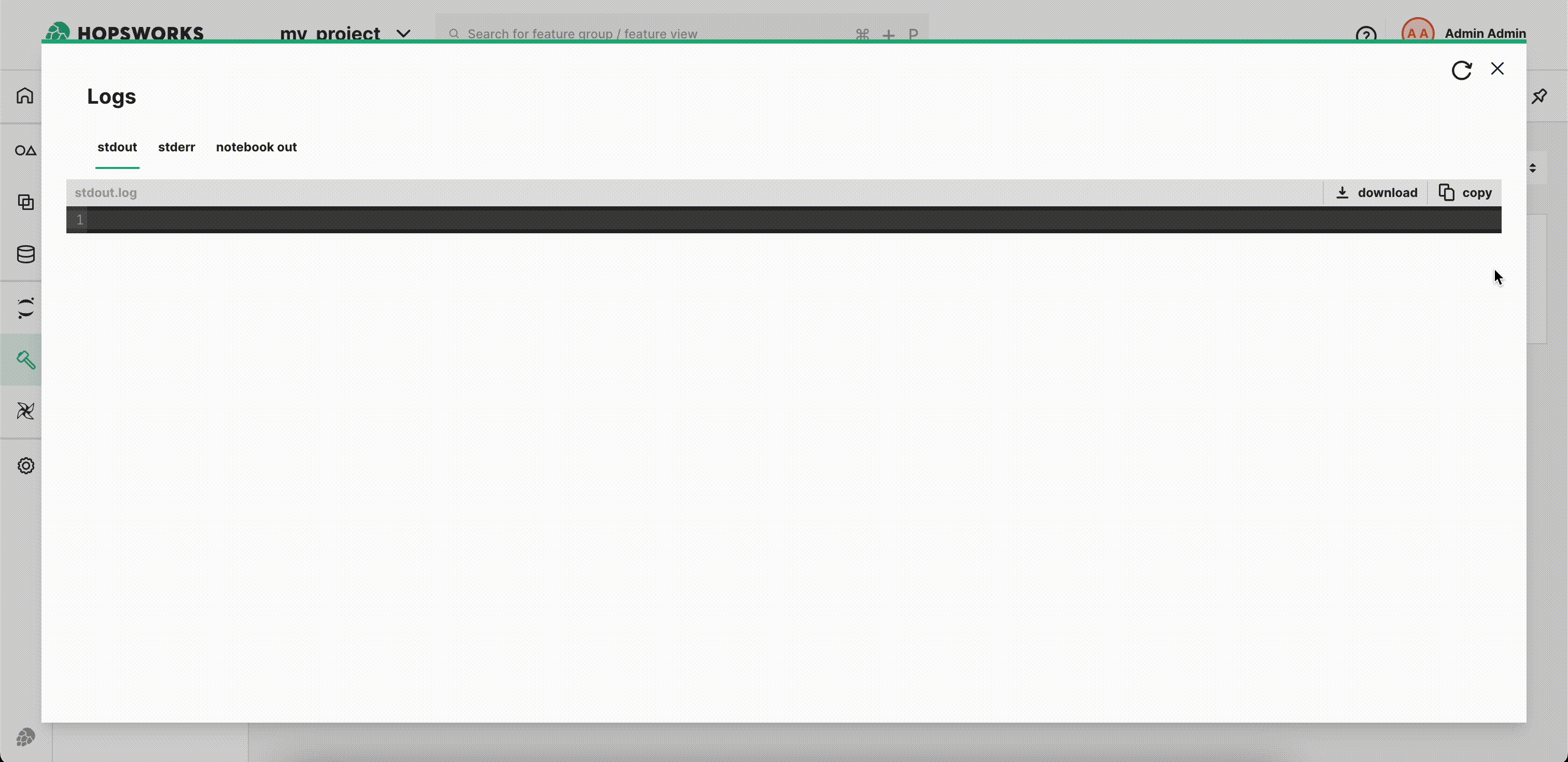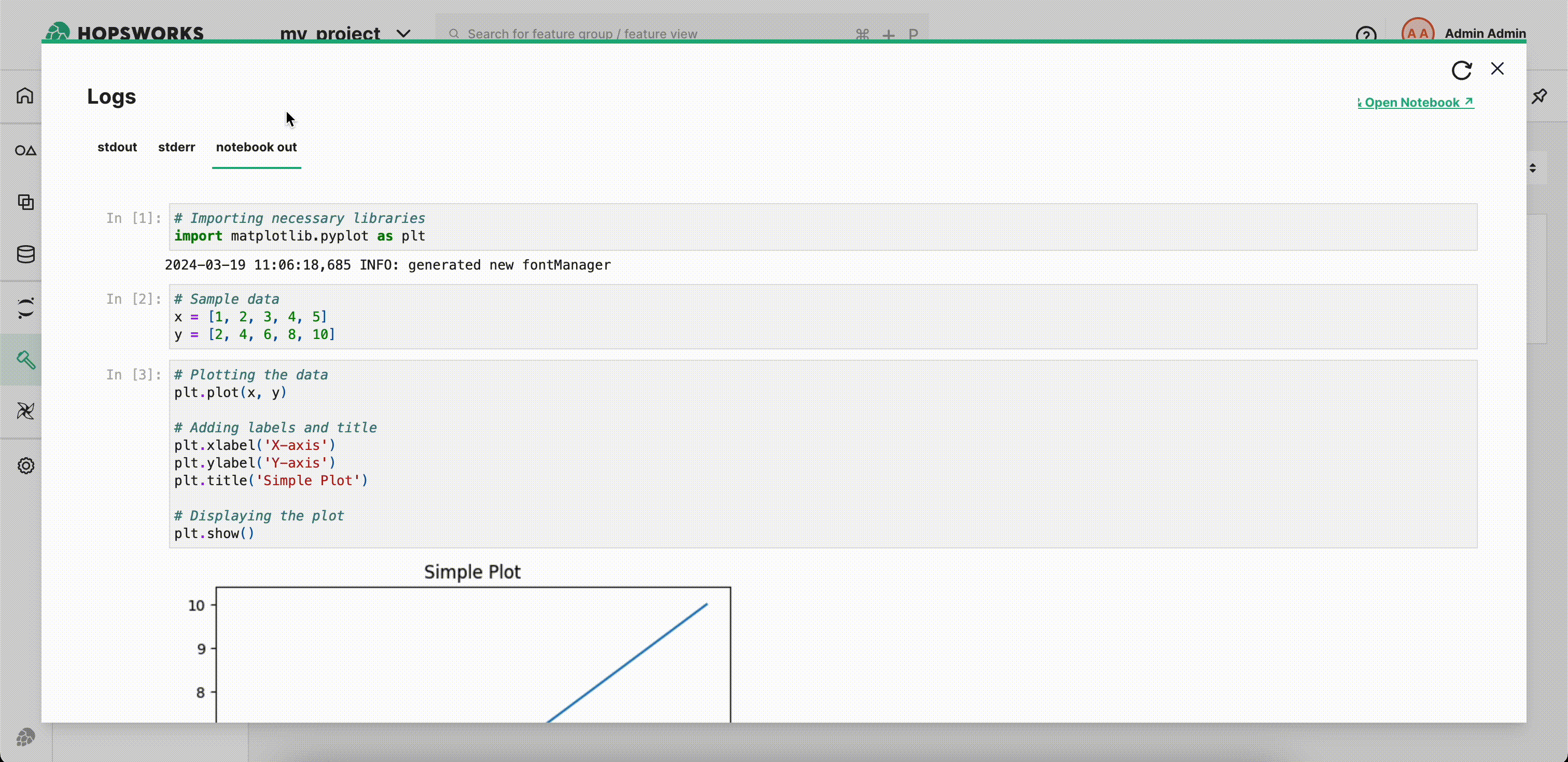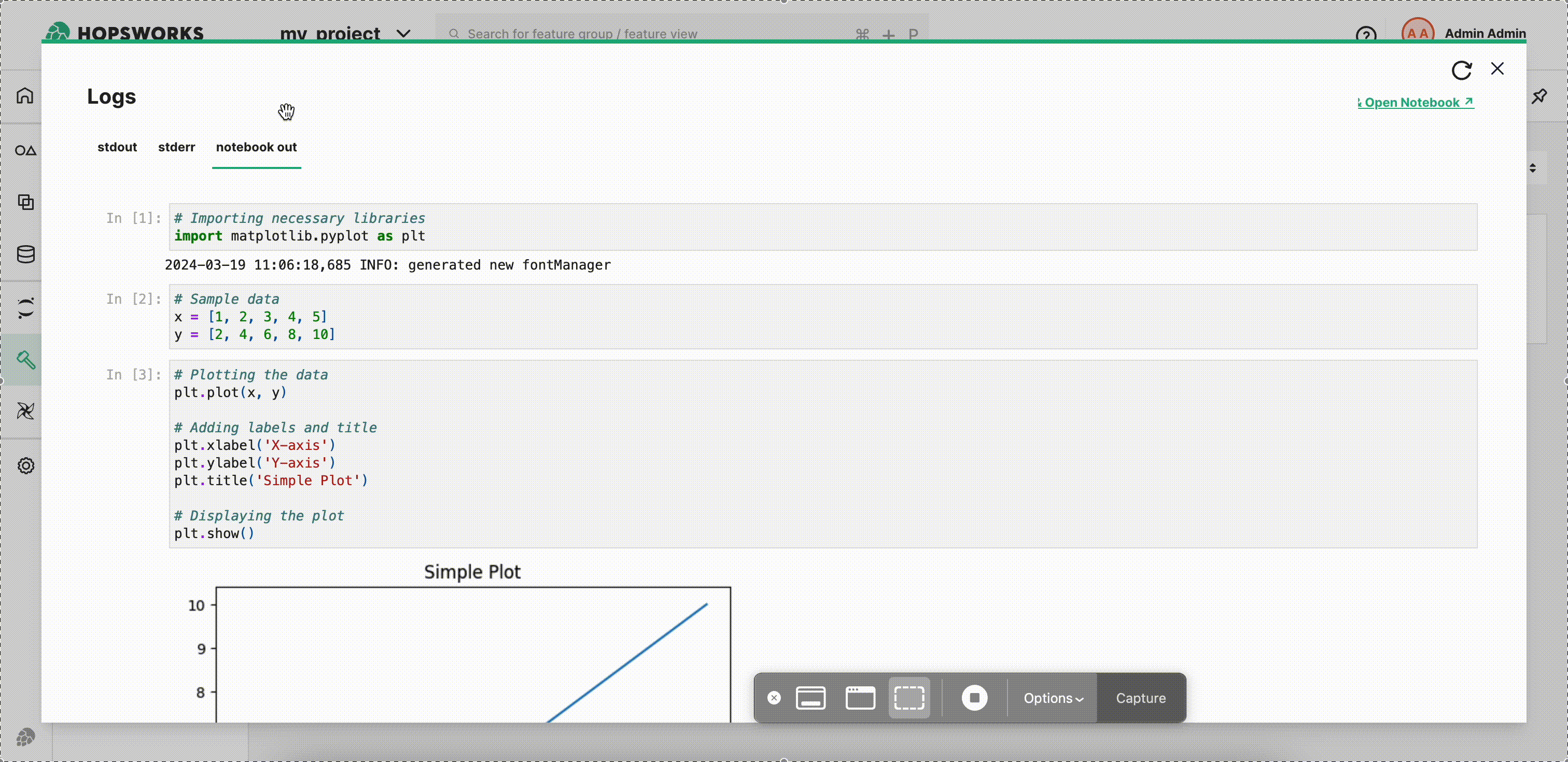
You can directly edit and save the output notebook by clicking Open Notebook.
Code#
Step 1: Upload the Jupyter Notebook script#
This snippet assumes the Jupyter Notebook script is in the current working directory and named notebook.ipynb.
It will upload the Jupyter Notebook script to the Resources dataset in your project.
import hopsworks
project = hopsworks.login()
dataset_api = project.get_dataset_api()
uploaded_file_path = dataset_api.upload("notebook.ipynb", "Resources")
Step 2: Create Jupyter Notebook job#
In this snippet we get the JobsApi object to get the default job configuration for a PYTHON job, set the jupyter notebook file and override the environment to run in, and finally create the Job object.
jobs_api = project.get_job_api()
notebook_job_config = jobs_api.get_configuration("PYTHON")
# Set the application file
notebook_job_config["appPath"] = uploaded_file_path
# Override the python job environment
notebook_job_config["environmentName"] = "python-feature-pipeline"
job = jobs_api.create_job("notebook_job", notebook_job_config)
Step 3: Execute the job#
In this code snippet, we execute the job with arguments and wait until it reaches a terminal state.
# Run the job
execution = job.run(args="-p a 2 -p b 5", await_termination=True)
Configuration#
The following table describes the job configuration parameters for a PYTHON job.
conf = jobs_api.get_configuration("PYTHON")
| Field | Type | Description | Default |
|---|---|---|---|
conf['type'] | string | Type of the job configuration | "pythonJobConfiguration" |
conf['appPath'] | string | Project relative path to notebook (e.g., Resources/foo.ipynb) | null |
conf['defaultArgs'] | string | Arguments to pass to the notebook. Will be overridden if arguments are passed explicitly via Job.run(args="...").Must conform to Papermill format -p arg1 val1 | null |
conf['environmentName'] | string | Name of the project Python environment to use | "pandas-training-pipeline" |
conf['resourceConfig']['cores'] | float | Number of CPU cores to be allocated | 1.0 |
conf['resourceConfig']['memory'] | int | Number of MBs to be allocated | 2048 |
conf['resourceConfig']['gpus'] | int | Number of GPUs to be allocated | 0 |
conf['logRedirection'] | boolean | Whether logs are redirected | true |
conf['jobType'] | string | Type of job | "PYTHON" |
conf['files'] | string | Comma-separated string of HDFS path(s) to files to be made available to the application. Example: hdfs:///Project/<project>/Resources/file1.py,... | null |
Accessing project data#
Recommended approach if /hopsfs is mounted
If your Hopsworks installation is configured to mount the project datasets under /hopsfs, which it is in most cases, then please refer to this section instead of the Additional files property to reference file resources.
Absolute paths#
The project datasets are mounted under /hopsfs, so you can access data.csv from the Resources dataset using /hopsfs/Resources/data.csv in your notebook. Shared datasets are accessible at /hopsfs/shared-datasets/<source-project>/<dataset-name> if HopsFS is mounted. The shared datasets directory is also available through the SHARED_DATASETS_DIR environment variable.
Relative paths#
The notebook's working directory is the folder it is located in. For example, if it is located in the Resources dataset, and you have a file named data.csv in that dataset, you simply access it using data.csv. Also, if you write a local file, for example output.txt, it will be saved in the Resources dataset.