Assuming a role#
When deploying Hopsworks on EC2 instances you might need to assume different roles to access resources on AWS. These roles are configured in AWS and mapped to projects in Hopsworks, for a guide on how to configure this see role mapping.
After an administrator configured role mappings in Hopsworks you can see the roles you can assume by going to your project settings.
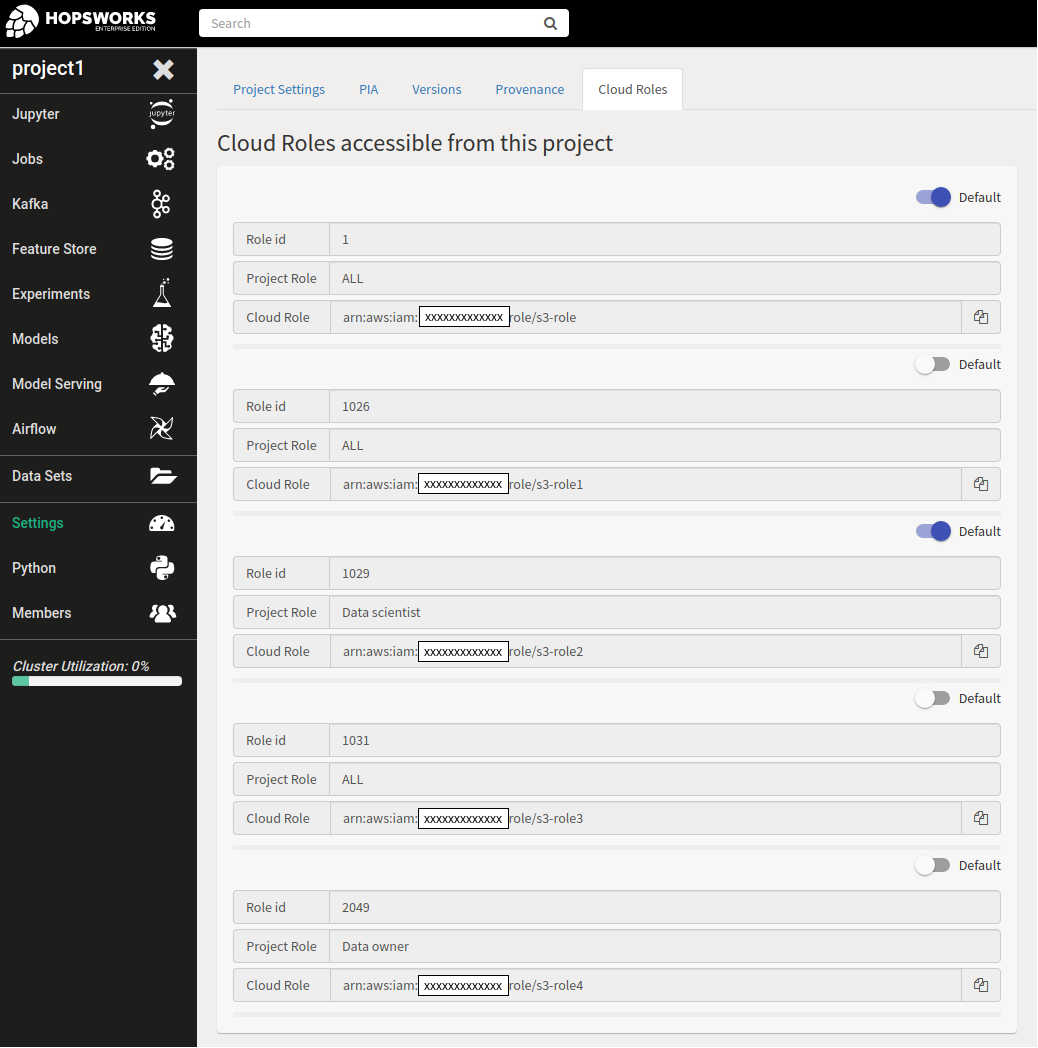
You can then use the Hops Python and Java APIs to assume the roles listed in your project's settings page.
When calling the assume role method you can pass the role ARN string or use the get role method that takes the role id as an argument. If you assign a default role for your project you can call the assume role method with no argument.
You can assign (if you are a Data owner in that project) a default role to you project by clicking on the Default button above the role you want to make default. You can set one default per project role. If a default is set for a project role (Data scientist or Data owner) and all members (ALL) the default set for the project role will take precedence over the default set for all members. In the image above if a Data scientist called the assume role method with no arguments she will assume the role with id 1029 but if a Data owner called the same method she will assume the role with id 1.
Use temporary credentials.
Python
from hops.credentials_provider import get_role, assume_role
credentials = assume_role(role_arn=get_role(1))
spark.read.csv("s3a://resource/test.csv").show()
import io.hops.util.CredentialsProvider
val creds = CredentialsProvider.assumeRole(CredentialsProvider.getRole(1))
spark.read.csv("s3a://resource/test.csv").show()
The assume role method sets spark hadoop configurations that will allow spark to read s3 buckets. The code examples above show how to read s3 buckets using Python and Scala.
Assume role also sets environment variables AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY and AWS_SESSION_TOKEN so that programs running in the container can use the credentials for the newly assumed role.
To read s3 buckets with TensorFlow you also need to set AWS_REGION environment variable (s3 bucket region). The code below shows how to read training and validation datasets from s3 bucket using TensorFlow.
Use temporary credentials with TensorFlow.
from hops.credentials_provider import get_role, assume_role
import tensorflow as tf
import os
assume_role(role_arn=get_role(1))
# s3 bucket region need to be set for TensorFlow
os.environ["AWS_REGION"] = "eu-north-1"
train_filenames = ["s3://resource/train/train.tfrecords"]
validation_filenames = ["s3://resourcet/validation/validation.tfrecords"]
train_dataset = tf.data.TFRecordDataset(train_filenames)
validation_dataset = tf.data.TFRecordDataset(validation_filenames)
for raw_record in train_dataset.take(1):
example = tf.train.Example()
example.ParseFromString(raw_record.numpy())
print(example)