Quickstart Guide#
The Hopsworks feature store is a centralized repository, within an organization, to manage machine learning features. A feature is a measurable property of a phenomenon. It could be a simple value such as the age of a customer, or it could be an aggregated value, such as the number of transactions made by a customer in the last 30 days.
A feature is not restricted to an numeric value, it could be a string representing an address, or an image.
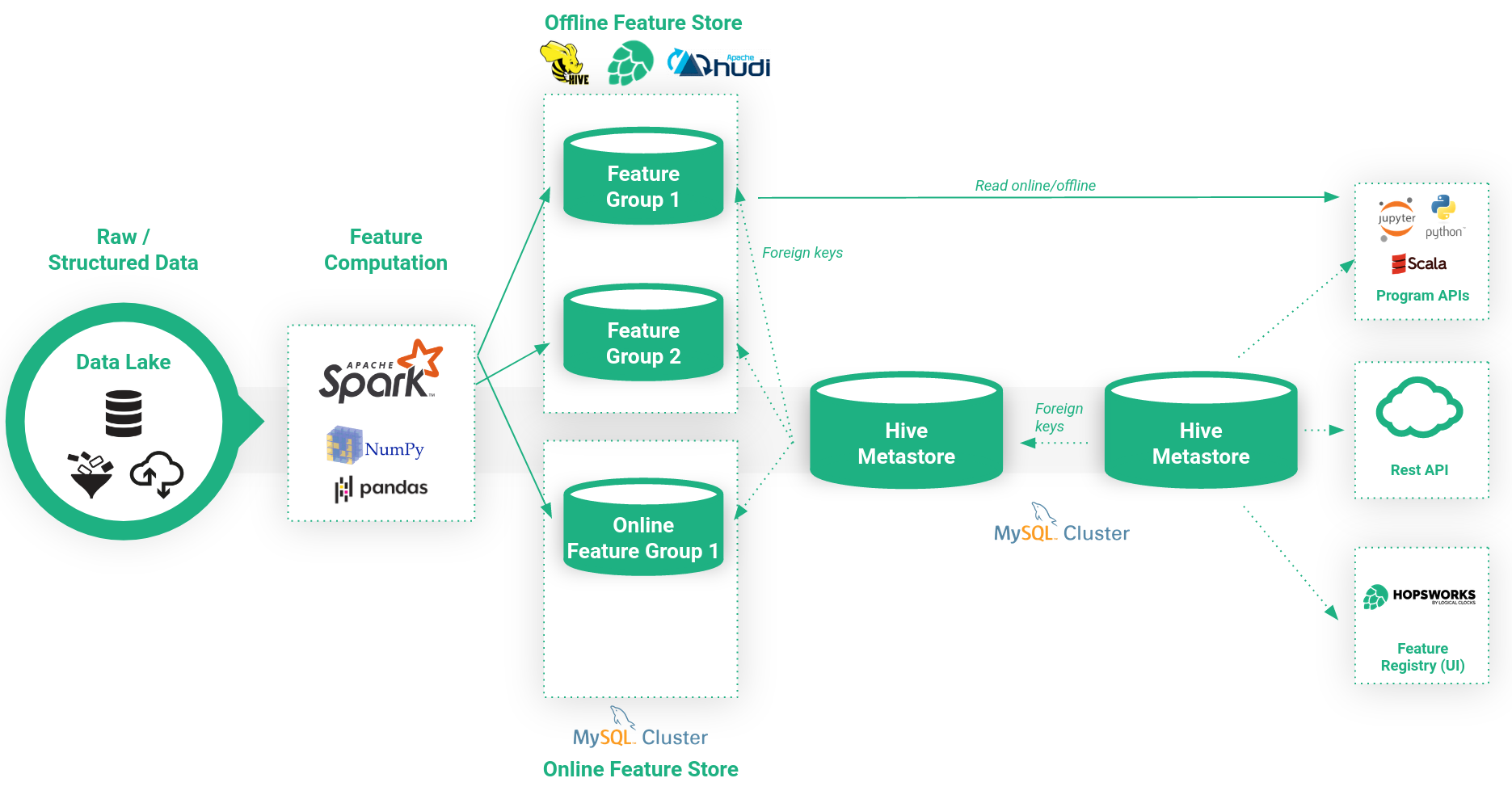
A feature store is not a pure storage service, it goes hand-in-hand with feature computation. Feature engineering is the process of transforming raw data into a format that is compatible and understandable for predictive models.
In this Quickstart Guide we are going to focus on the left side of the picture above. In particular how data engeneers can create features and push them to the Hopsworks feature store so that they are available to the data scientists
HSFS library#
The Hopsworks feature feature store library is called hsfs (Hopsworks Feature Store).
The library is Apache V2 licensed and available here. The library is currently available for Python and JVM languages such as Scala and Java.
If you want to connect to the Feature Store from outside Hopsworks, see our integration guides.
The library is build around metadata-objects, representing entities within the Feature Store. You can modify metadata by changing it in the metadata-objects and subsequently persisting it to the Feature Store. In fact, the Feature Store itself is also represented by an object. Furthermore, these objects have methods to save data along with the entities in the feature store. This data can be materialized from Spark or Pandas DataFrames, or the HSFS-Query abstraction.
Guide Notebooks#
This guide is based on a series of notebooks, which is available in the Feature Store Demo Tour Project on Hopsworks.
Connection, Project and Feature Store#
The first step is to establish a connection with your Hopsworks Feature Store instance and retrieve the object that represents the Feature Store you'll be working with.
By default connection.get_feature_store() returns the feature store of the project you are working with. However, it accepts also a project name as parameter to select a different feature store.
import hsfs
# Create a connection
connection = hsfs.connection()
# Get the feature store handle for the project's feature store
fs = connection.get_feature_store()
import com.logicalclocks.hsfs._
import scala.collection.JavaConverters._
// Create a connection
val connection = HopsworksConnection.builder().build();
// Get the feature store handle for the project's feature store
val fs = connection.getFeatureStore();
You can inspect the Feature Store's meta data by accessing its attributes:
print(fs.name)
print(fs.description)
println(fs.getName)
println(fs.getDescription)
Example Data#
In order to use the example data, you need to unzip the archive.zip file which is located in /Jupyter/hsfs/ when you are running the Quickstart from the Feature Store Demo Tour project. To do so, head to the Data Sets tab in Hopsworks, open the /Jupyter/hsfs directory, mark the archive.zip-file and click the extract button.
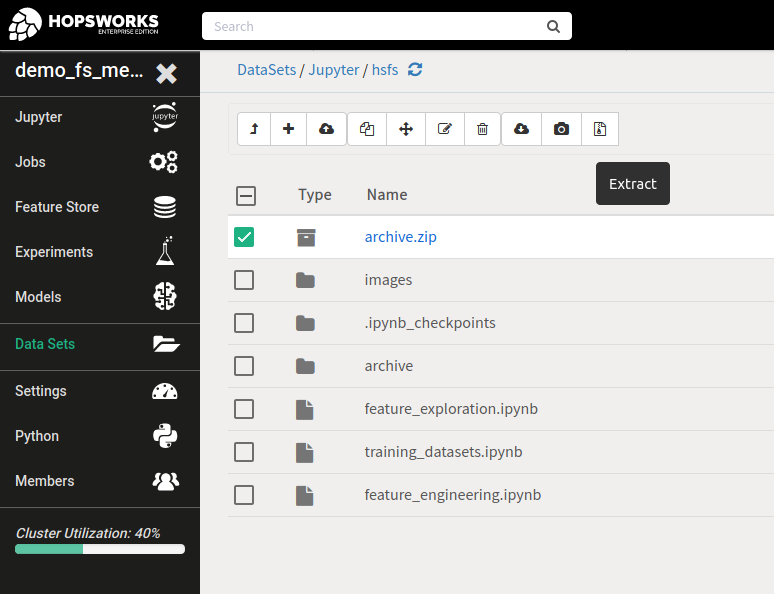
Of course you can also use your own data if you read it into a Spark DataFrame.
Feature Groups#
Assuming you have done some feature engineering on the raw data, having produced a DataFrame with Features, these can now be saved to the Feature Store. For examples of feature engineering on the provided Sales data, see the example notebook.
Creation#
Create a feature group named store_fg. The store is the primary key uniquely identifying all the remaining features in this feature group. As you can see, you have the possibility to make settings on the Feature Group, such as the version number, or the statistics which should be computed. The Feature Group Guide guides through the full configuration of Feature Groups.
store_fg_meta = fs.create_feature_group(name="store_fg",
version=1,
primary_key=["store"],
description="Store related features",
statistics_config={"enabled": True, "histograms": True, "correlations": True})
val storeFgMeta = (fs.createFeatureGroup()
.name("store_fg")
.description("Store related features")
.version(1)
.primaryKeys(Seq("store").asJava)
.statisticsEnabled(True)
.histograms(True)
.correlations(True)
.build())
Up to this point we have just created the metadata object representing the feature group. However, we haven't saved the feature group in the feature store yet. To do so, we can call the method save on the metadata object created in the cell above.
store_fg_meta.save(store_dataframe)
storeFgMeta.save(store_dataframe)
Retrieval#
If there were feature groups previously created in your Feature Store, or you want to pick up where you left off before, you can retrieve and read feature groups in a similar fashion as creating them: Using the Feature Store object, you can retrieve handles to the entities, such as feature groups, in the Feature Store. By default, this will return the first version of an entity, if you want a more recent version, you need to specify the version. This is necessary, in order to make the code reproducible, as version changes indicate breaking schema changes.
exogenous_fg_meta = fs.get_feature_group('exogenous_fg', version=1)
# Read the data, by default selecting all features
exogenous_df = exogenous_fg_meta.read()
# Select a subset of features and read into dataframe
exogenous_df_subset = exogenous_fg_meta.select(["store", "fuel_price", "is_holiday"]).read()
val exogenousFgMeta= fs.getFeatureGroup("exogenous_fg", 1)
// Read the data, by default selecting all features
val exogenousDf = exogenousFgMeta.read()
// Select a subset of features and read into dataframe
val exogenousDfSubset = exogenousFgMeta.select(Seq("store", "fuel_price", "is_holiday").asJava).read()
Joining#
HSFS provides an API similar to Pandas to join feature groups together and to select features from different feature groups. The easies query you can write is by selecting all the features from a feature group and join them with all the features of another feature group.
You can use the select_all() method of a feature group to select all its features. HSFS relies on the Hopsworks feature store to identify which features of the two feature groups to use as joining condition.
If you don't specify anything, Hopsworks will use the largest matching subset of primary keys with the same name.
In the example below, sales_fg has store, dept and date as composite primary key while exogenous_fg has only store and date. So Hopsworks will set as joining condition store and date.
sales_fg = fs.get_feature_group('sales_fg')
exogenous_fg = fs.get_feature_group('exogenous_fg')
query = sales_fg.select_all().join(exogenous_fg.select_all())
# print first 5 rows of the query
query.show(5)
val exogenousFg = fs.getFeatureGroup("exogenous_fg")
val salesFg = fs.getFeatureGroup("sales_fg")
val query = salesFg.selectAll().join(exogenousFg.selectAll())
// print first 5 rows of the query
query.show(5)
For a more complex joins, and details about overwriting the join keys and join type, the programming interface guide explains the Query interface as well as
Training Datasets#
Once a Data Scientist has found the features she needs for her model, she can create a training dataset to materialize the features in the desired file format. The Hopsworks Feature Store supports a variety of file formats, matching the Data Scientists' favourite Machine Learning Frameworks.
Creation#
You can either create a training dataset from a Query object or directly from a Spark or Pandas DataFrame. Spark and Pandas give you more flexibility, but it has drawbacks for reproducability at inference time, when the Feature Vector needs to be reconstructed. The idea of the Feature Store is to have ready-engineered features available for Data Scientists to be selected for training datasets. With this assumption, it should not be necessary to perform additional engineering, but instead joining, filtering and point in time querying should be enough to generate training datasets.
store_fg = fs.get_feature_group("store_fg")
sales_fg = fs.get_feature_group('sales_fg')
exogenous_fg = fs.get_feature_group('exogenous_fg')
query = sales_fg.select_all() \
.join(store_fg.select_all()) \
.join(exogenous_fg.select(['fuel_price', 'unemployment', 'cpi']))
td = fs.create_training_dataset(
name = "sales_model",
description = "Dataset to train the sales model",
data_format = "tfrecord",
splits = {"train": 0.7, "test": 0.2, "validate": 0.1},
version = 1)
td.save(query)
val storeFg = fs.getFeatureGroup("store_fg")
val exogenousFg = fs.getFeatureGroup("exogenous_fg")
val salesFg = fs.getFeatureGroup("sales_fg")
query = (salesFg.selectAll()
.join(storeFg.selectAll())
.join(exogenousFg.select(Seq("fuel_price", "unemployment", "cpi").asJava)))
val td = (fs.createTrainingDataset()
.name("sales_model")
.description("Dataset to train the sales model")
.version(1)
.dataFormat(DataFormat.TFRECORD)
.splits(Map("train" -> Double.box(0.7), "test" -> Double.box(0.2), "validate" -> Double.box(0.1))
.build())
td.save(query)
Retrieval#
If you want to use a previously created training dataset to train a machine learning model, you can get the training dataset similarly to how you get a feature group.
td = fs.get_training_dataset("sales_model")
df = td.read(split="train")
val td = fs.getTrainingDataset("sales_model")
val df = td.read("train")
Either you read the data into a DataFrame again, or you use the provided utility methods, to instantiate for example a tf.data.Dataset, which can directly be passed to a TensorFlow model.
train_input_feeder = training_dataset.feed(target_name="label",
split="train",
is_training=True)
train_input = train_input_feeder.tf_record_dataset()
This functionality is only available in the Python API.