Concept Overview#
Project-Based Multi-tenancy#
Hopsworks implements a dynamic role-based access control model through a project-based multi-tenant security model. Inspired by GDPR, in Hopsworks a Project is a sandboxed set of users, data, and programs (where data can be shared in a controlled manner between projects). Every Project has an owner with full read-write privileges and zero or more members.
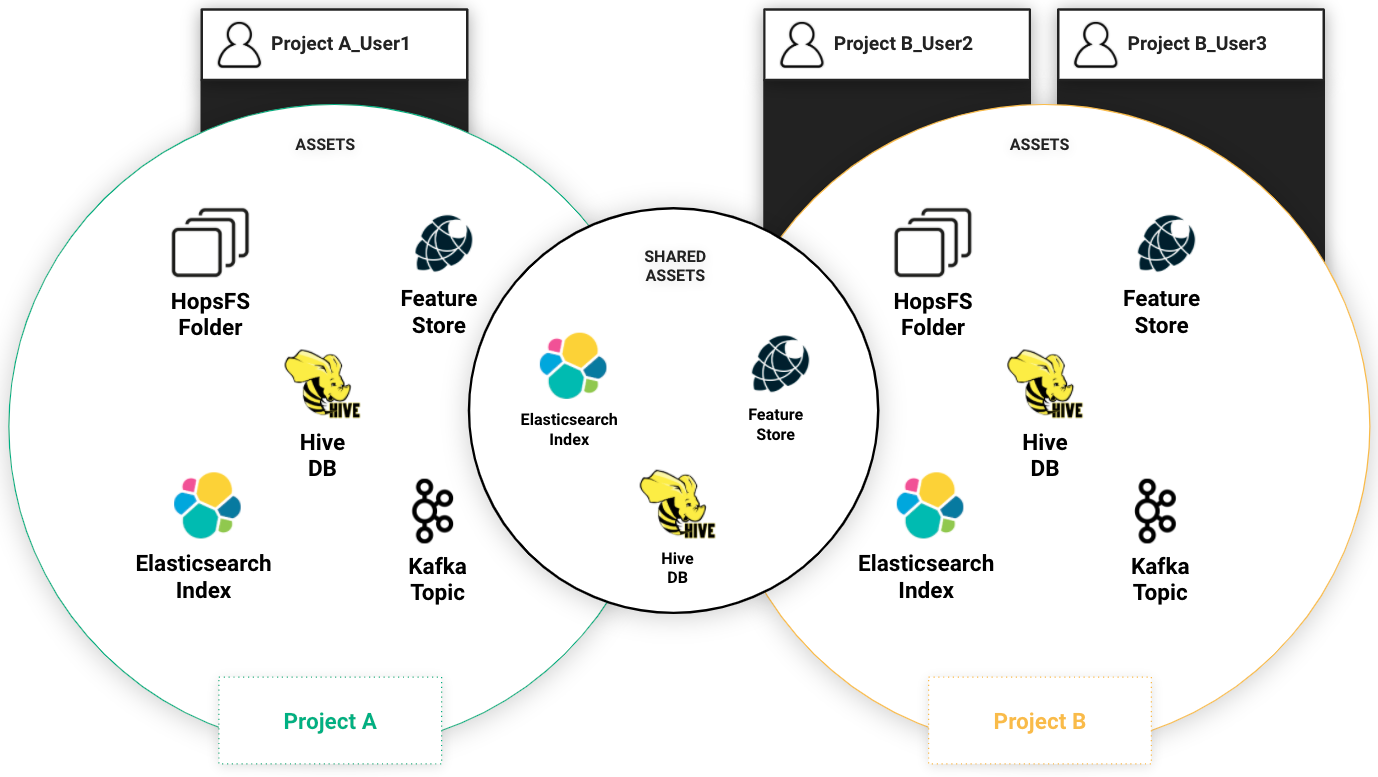
An important aspect of Project based multi-tenancy is that assets can be shared between projects. The current assets that can be shared between projects are: files/directories in HopsFS, Hive databases, feature stores, and Kafka topics.
Important
Sharing assets does not mean that data is duplicated.
The Hopsworks Feature Store#
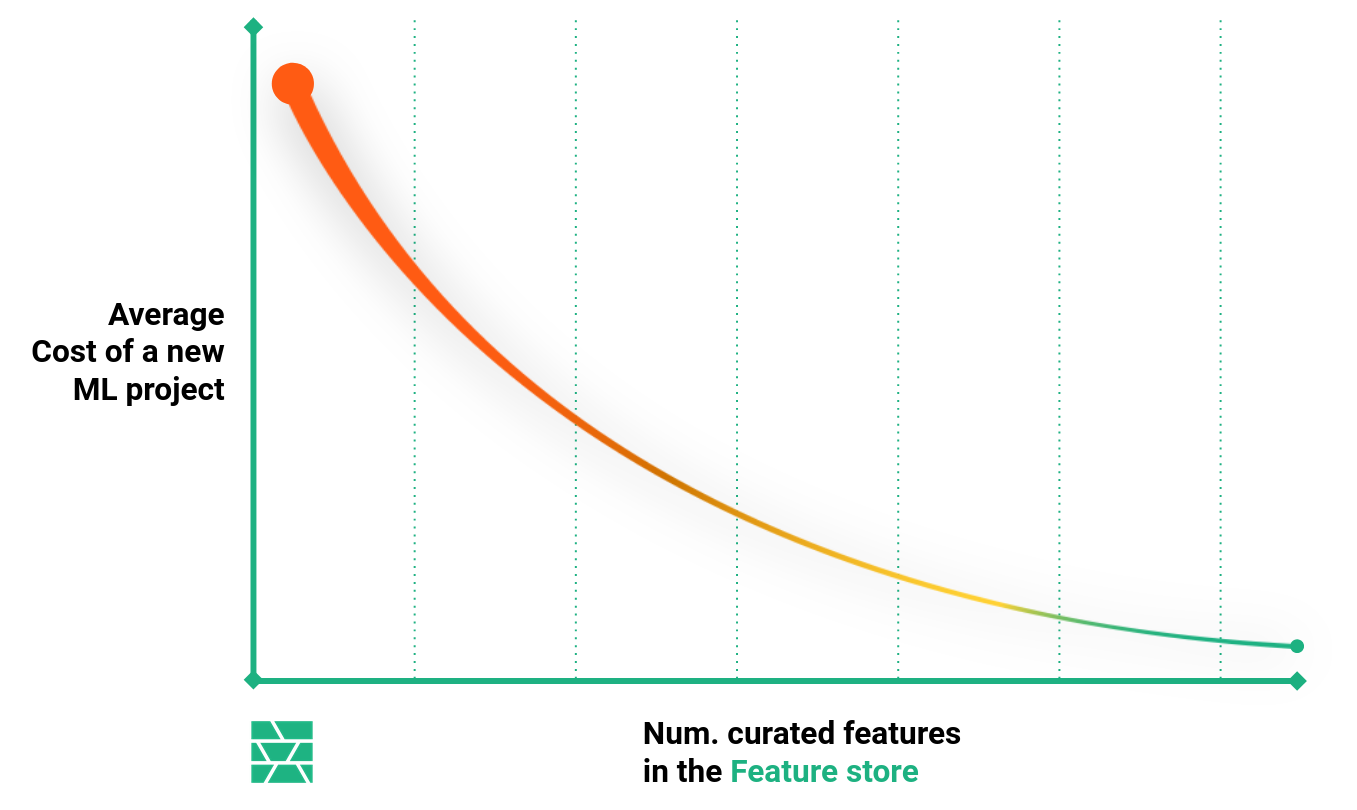
The Hopsworks Feature Store is a tool for curating and serving machine learning (ML)features.
The Feature Store is a central and unified API between Data Engineers and Data Scientists.
Benefits of the Feature Store
- Manage feature data to profive unified access to machine learning features from small teams to large enterprises.
- Enable discovery, documentation, sharing and insights into your features through rich metadata.
- Make feature data available in a performant and scalable way for model training and model inference.
- Allow point-in-time correct and consistent access to feature data (time travel).
Feature Store Concepts#
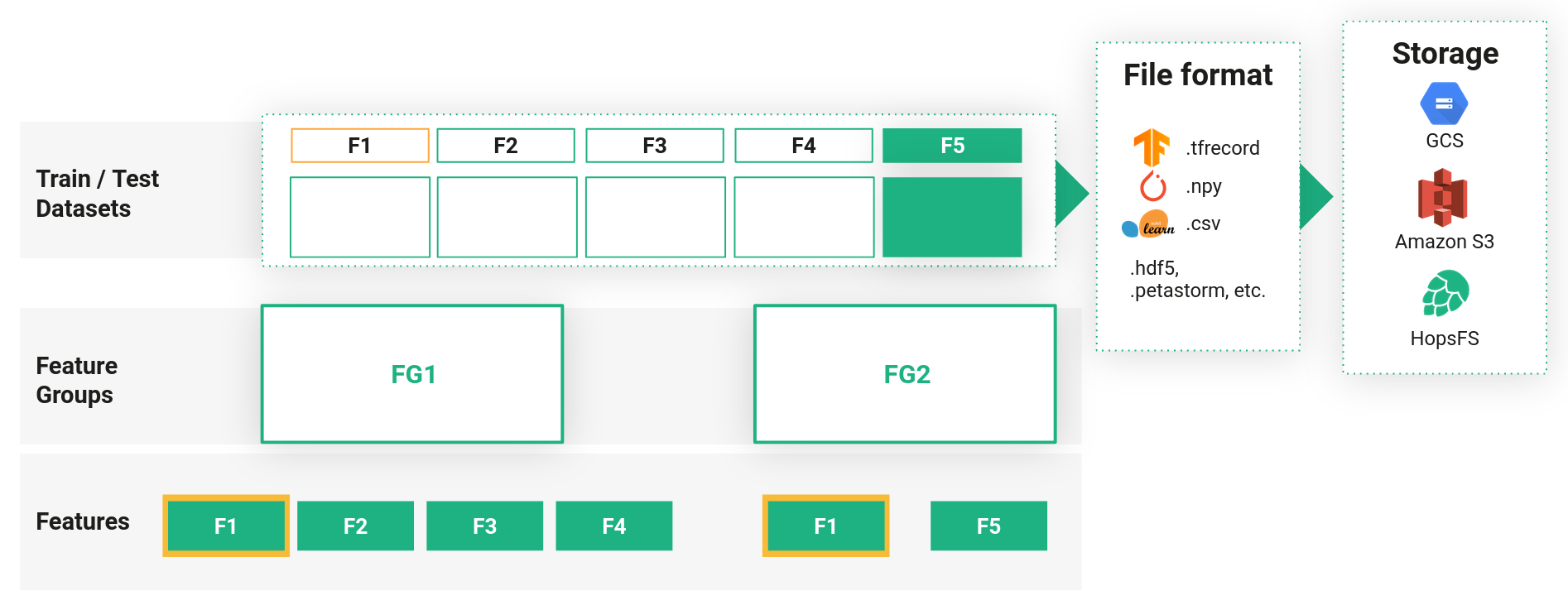
Entities within the Feature Store are organized hierarchically. On the most granular level are the features itself. Data Engineers ingest the feature data within their organization through the creation of feature groups. Data Scientists are then able to read selected features from the feature groups to create training datasets for model training, run batch inference with deployed models or perform inference from online models by scoring single feature vectors.
Feature Vector
A Feature Vector is a single row of feature values associated with a primary key.
Feature Groups#
Feature Groups are entities that contain both metadata about the grouped features, as well as information of the jobs used to ingest the data contained in a feature group and also the actual location of the data (HopsFS or externally, such as S3). Typically, feature groups represent a logical set of features coming from the same data source sharing a common primary key. Feature groups also contain the schema and type information of the features, for the user to know how to interpret the data.
Feature groups can also be used to compute Statistics over features, or to define Data Validation Rules using the statistics and schema information.
In order to enable online serving for features of a feature group, the feature group needs to be made available as an online feature group.
Training Datasets#
In order to be able to train machine learning models efficiently, the feature data needs to be materialized as a Training Dataset in the file format most suitable for the ML framework used. For example, when training models with TensorFlow the ideal file format is TensorFlow's tfrecord format.
Training datasets can be created with features from any number of feature groups, as long as the feature groups can be joined in a meaningful way.
Users are able to compute Statistics also for training datasets, which will make it easy to understand a dataset's characteristics also in the future.
The Hopsworks Feature Store has support for writing training datasets either to the distributed file system of Hopsworks - HopsFS - or to external storage such as S3.
Offline vs. Online Feature Store#
The Feature Store is a dual database-system, to cover all machine learning use cases it consists of high throughput offline storage layer, and additionally a low-latency online storage. The offline storage is mainly used to generate large batches of feature data, for example to be exported as training datasets. Additionally, the offline storage can be used to score large amounts of data with a machine learning model in regular intervals, so called batch inference. The online storage on the other hand is required for online applications, where the goal is to retrieve a single feature vector with the same logic as was applied to generate the training dataset, such that the vector can subsequently be passed to a machine learning model in production to compute a prediction. An example for online inference would be an e-commerce business, which would like to predict the credit score of a client when he is about to checkout his shopping cart. A client-id will be sent to the online feature store to retrieve the historic features for this customer, which can then be enriched by real time features like the value of his shopping cart, and will then be passed to the machine learning model for inference.
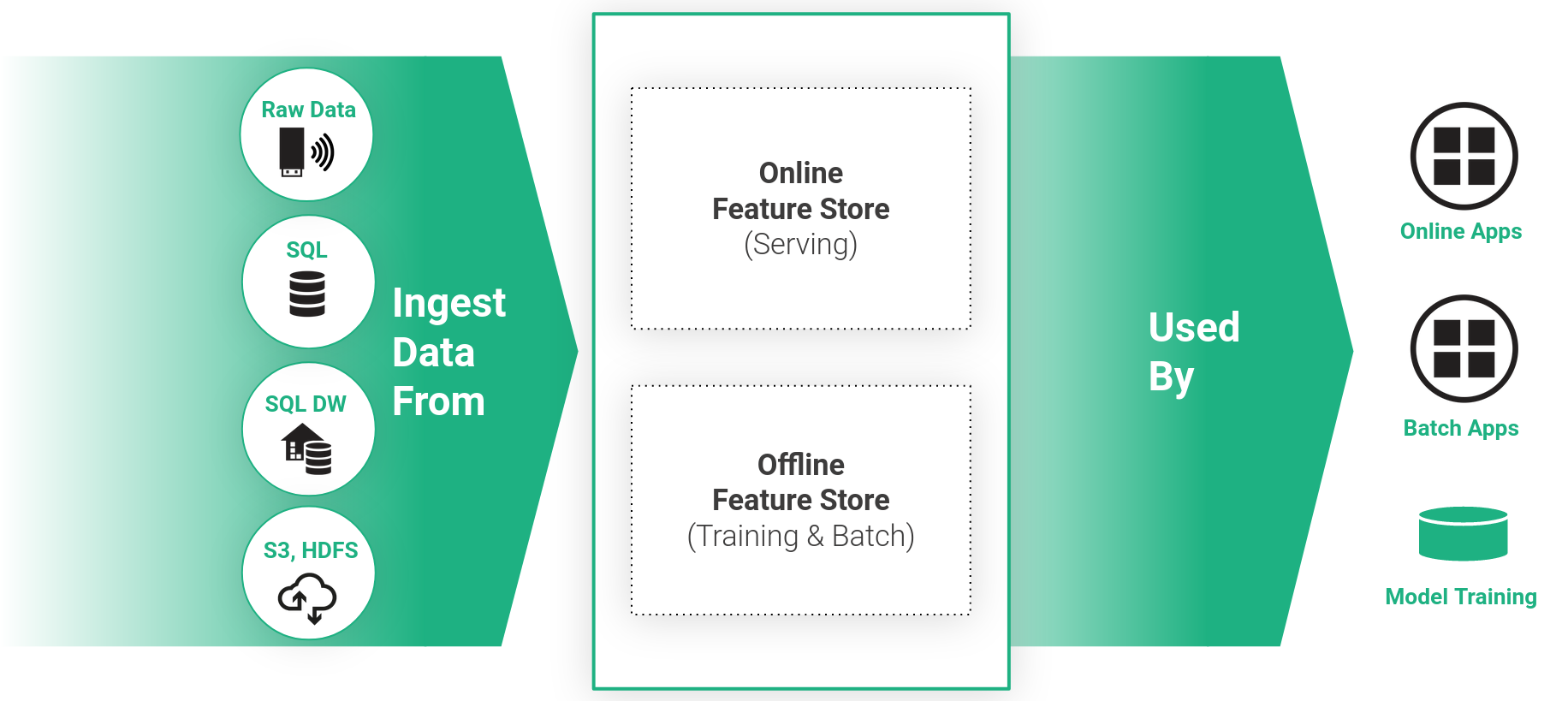
There is no database fullfilling both requirements of very low latency and and high throughput. Therefore, the Hopsworks Feature Store builds on Apache Hive with Apache Hudi as offline storage layer and MySQL Cluster (NDB) as online storage.