Managed RonDB#
For applications where Feature Store's performance and scalability is paramount we give users the option to create clusters with Managed RonDB. You don't need to worry about configuration as managed.hopsworks.ai will automatically pick the best options for your setup.
Single node RonDB#
The minimum setup for a Hopsworks cluster is to run all database services on their own virtual machine additionally to the Head node. This way the database can scale independently and does not affect other cluster services.
Note
For cluster versions <= 2.5.0 the database services run on Head node
RonDB cluster#
To setup a cluster with multiple RonDB nodes, select RonDB cluster during cluster creation. If this option is not available contact us.
General#
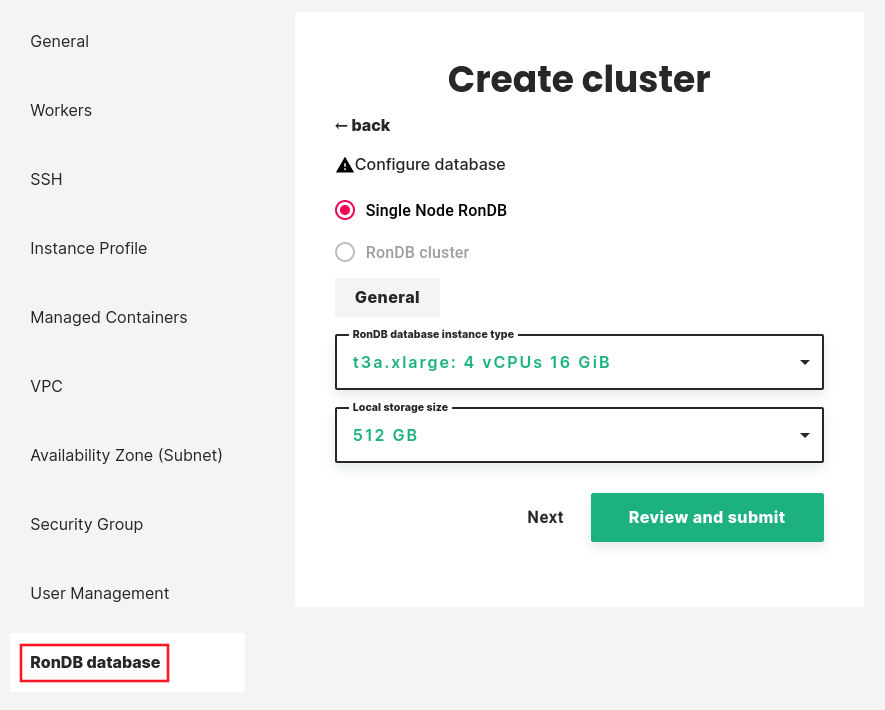
If you enable Managed RonDB you will see a basic configuration page where you can configure the database nodes.
Data node#
First, you need to select the instance type and local storage size for the data nodes. These are the database nodes that will store data. RonDB is an in-memory database, so in order to fit more data you need to choose an instance type with more memory. Local storage is used for offline storage of recovery data, and requires a disk at least 40 GiB plus 1.8 times the memory size of the data node VM.
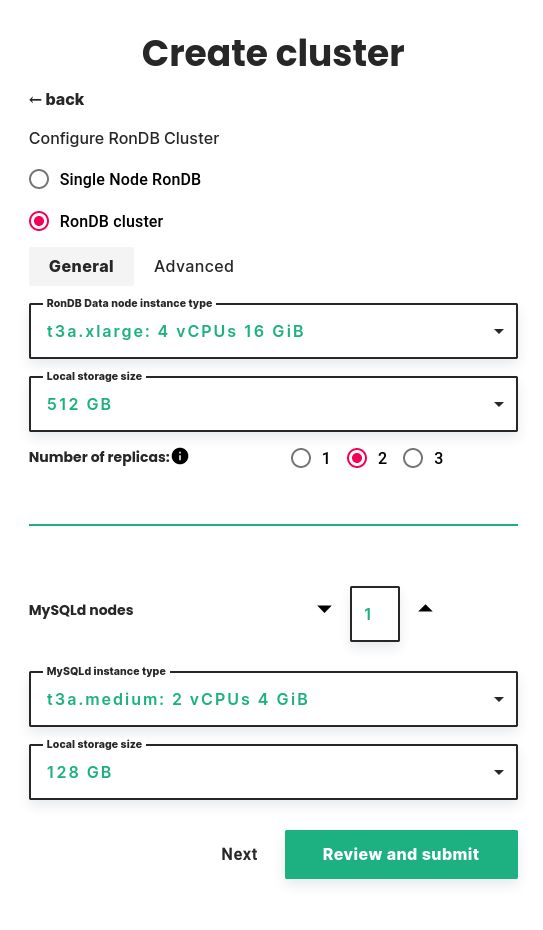
Number of replicas#
Next you need to select the number of replicas. This is the number of copies the cluster will maintain of your data.
- Choosing 1 replica is the cheapest option since it requires the lowest number of nodes, but this way you don't have High Availability. Whenever any of the nodes in the cluster fails the cluster will also fail, so only choose 1 replica if you are willing to accept cluster failure.
- The default and recommended is 2 replicas, which allows the cluster to continue operating after any one node fails.
- With 3 replicas, the cluster can continue operating after any two node failures that happen after each other.
MySQLd nodes#
Next you can configure the number of MySQLd nodes. These are dedicated nodes for performing SQL queries against your RonDB cluster. In many use cases you can choose zero, since the cluster's Head node already comes with a MySQL server. If you expect high load on MySQL servers, for example if you intend to run a custom streaming application that performs SQL queries in short intervals, then you can add more.
If you select at least one MySQLd node, you then get to select the instance type and local storage size for the MySQLd nodes.
Advanced#
The advanced tab offers less common options. We recommend keeping the defaults unless you know what you are doing.
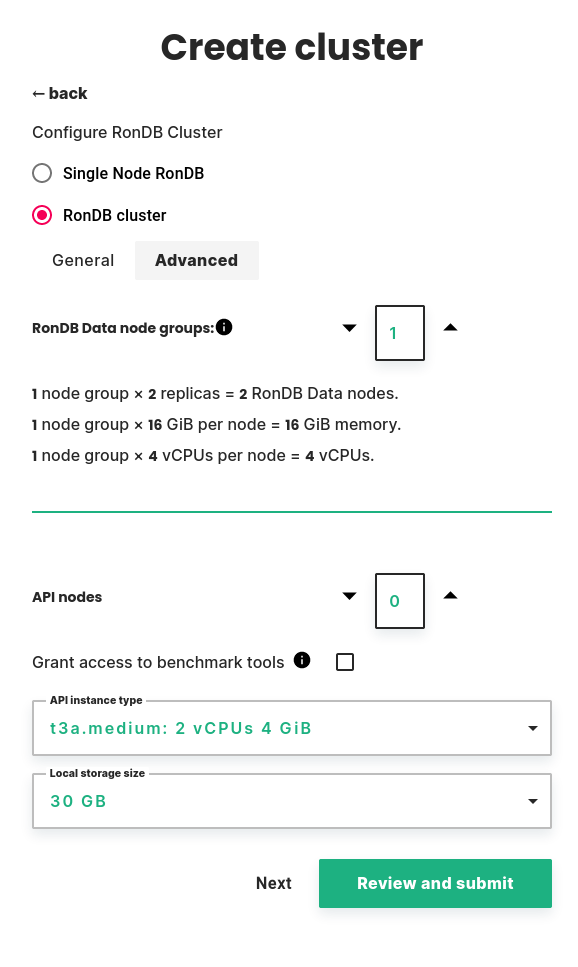
RonDB Data node groups#
You can choose the number of node groups, also known as database shards. The default is 1 node group, which means that all nodes will have a complete copy of all data. Increasing the number of node groups will split the data evenly. This way, you can create a cluster with higher capacity than a single node. For use cases where it is possible, we recommend using 1 node group and choose an instance type with enough memory to fit all data.
Below the number of node groups, you will see a summary of cluster resources.
- The number of data nodes is an important consideration for the cost of the cluster. It is calculated as the number of node groups multiplied by the number of replicas.
- The memory available to the cluster is calculated as the number of node groups multiplied by the memory per node. Note that the number replicas does not affect the available memory.
- The CPUs available to the cluster is calculated as the number of node groups multiplied by the number of CPUs per node. Note that the number replicas does not affect the available CPUs.
API nodes#
API nodes are specialized nodes which can run user code connecting directly to RonDB datanodes for increased performance.
You can choose the number of nodes, the instance type and local storage size.
There is also a checkbox to grant access to benchmark tools. This will let a benchmark user access specific database tables, so that you can benchmark RonDB safely.
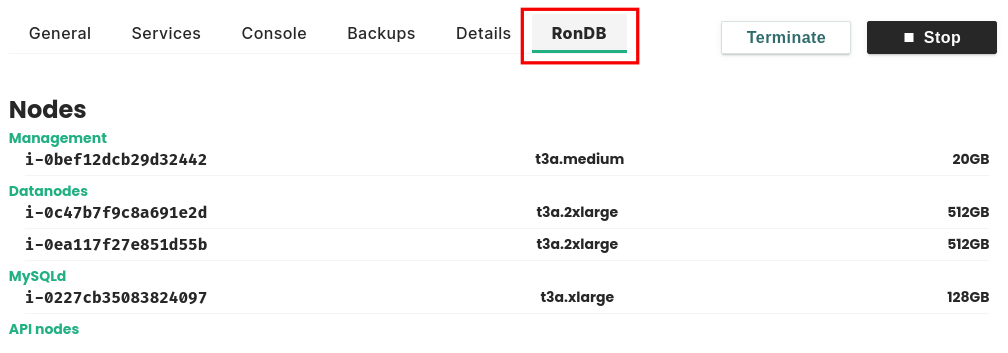
RonDB details#
Once the cluster is created you can view some details by clicking on the RonDB tab as shown in the picture below.