How to create an External Feature Group#
Introduction#
In this guide you will learn how to create and register an external feature group with Hopsworks. This guide covers creating an external feature group using the HSFS APIs as well as the user interface.
Prerequisites#
Before you begin this guide we suggest you read the External Feature Group concept page to understand what a feature group is and how it fits in the ML pipeline.
Create using the HSFS APIs#
Retrieve the storage connector#
To create an external feature group using the HSFS APIs you need to provide an existing storage connector.
connector = feature_store.get_storage_connector("connector_name")
Create an External Feature Group#
SQL based external feature group#
query = """
SELECT TO_NUMERIC(ss_store_sk) AS ss_store_sk
, AVG(ss_net_profit) AS avg_ss_net_profit
, SUM(ss_net_profit) AS total_ss_net_profit
, AVG(ss_list_price) AS avg_ss_list_price
, AVG(ss_coupon_amt) AS avg_ss_coupon_amt
, sale_date
, ss_store_sk
FROM STORE_SALES
GROUP BY ss_store_sk, sales_date
"""
fg = feature_store.create_external_feature_group(name="sales",
version=1,
description="Physical shop sales features",
query=query,
storage_connector=connector,
primary_key=['ss_store_sk'],
event_time='sale_date'
)
Data Lake based external feature group#
fg = feature_store.create_external_feature_group(name="sales",
version=1,
description="Physical shop sales features",
data_format="parquet",
storage_connector=connector,
primary_key=['ss_store_sk'],
event_time='sale_date'
)
The full method documentation is available here. name is a mandatory parameter of the create_external_feature_group and represents the name of the feature group.
The version number is optional, if you don't specify the version number the APIs will create a new version by default with a version number equals to the highest existing version number plus one.
If the storage connector is defined for a data warehouse (e.g. JDBC, Snowflake, Redshift) you need to provide a SQL statement that will be executed to compute the features. If the storage connector is defined for a data lake, the location of the data as well as the format need to be provided.
Additionally we specify which columns of the DataFrame will be used as primary key, and event time. Composite primary keys are also supported.
Register the metadata#
The snippet above only created the metadata object on the Python interpreter running the code. To register the external feature group metadata with Hopsworks, you should invoke the save method:
fg.save()
Limitations#
Hopsworks Feature Store does not support time-travel capabilities for on-demand feature groups. Moreover, as the data resides on external systems, on-demand feature groups cannot be made available online for low latency serving. To make data from an on-demand feature group available online, users need to define an online enabled feature group and hava a job that periodically reads data from the on-demand feature group and writes in the online feature group.
Python support
Currently the HSFS library does not support calling the read() or show() methods on on-demand feature groups. Likewise it is not possibile to call the read() or show() methods on queries containing on-demand feature groups. Nevertheless, on-demand feature groups can be used from a Python engine to create training datasets.
API Reference#
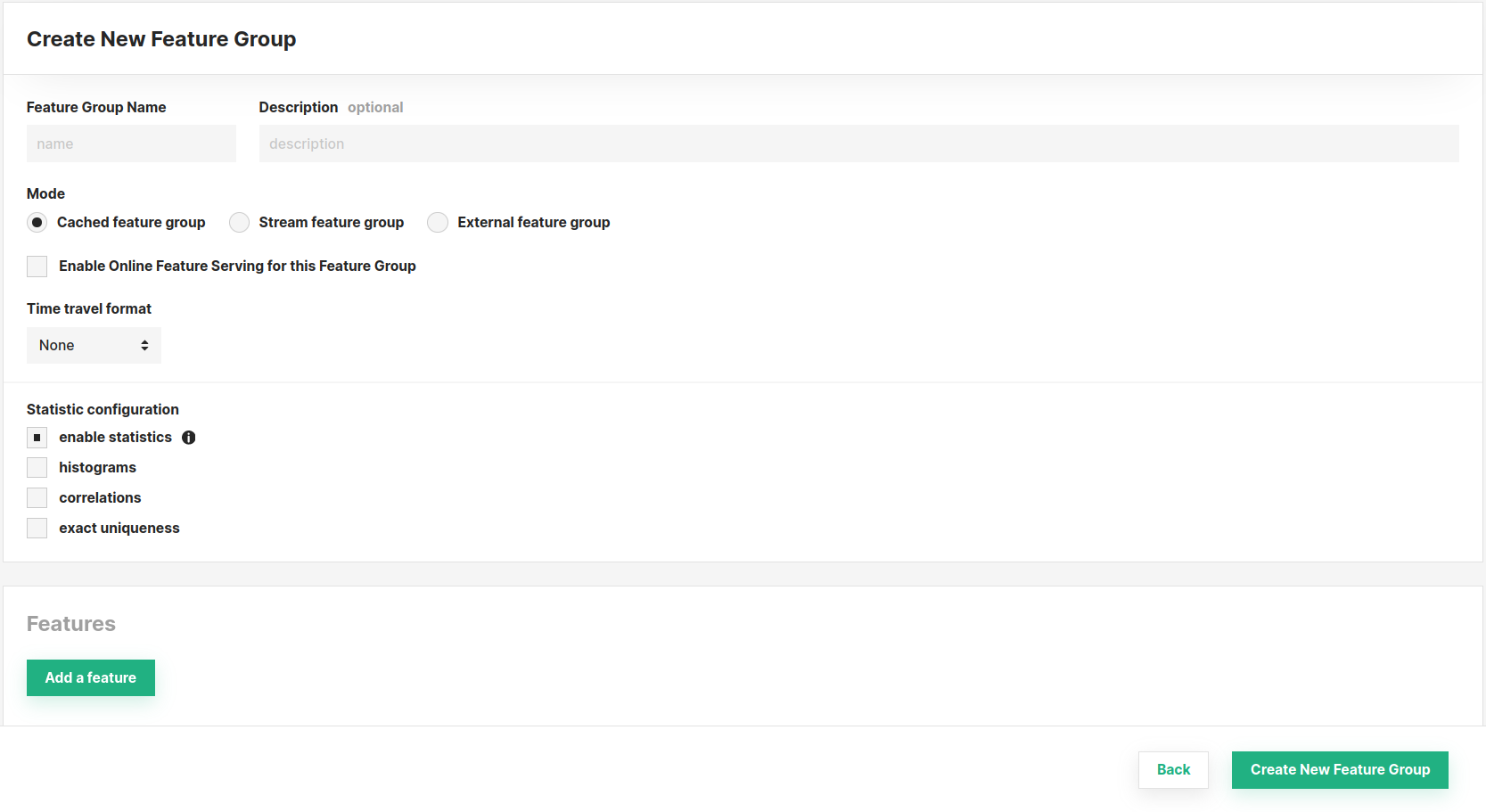
Create using the UI#
You can also create a new feature group through the UI. For this, navigate to the Feature Groups section and press the Create button at the top-right corner.

Subsequently, you will be able to define its properties (such as name, mode, features, and more). Refer to the documentation above for an explanation of the parameters available, they are the same as when you create a feature group using the SDK. Finally, complete the creation by clicking Create New Feature Group at the bottom of the page.