How To Configure A Predictor#
Introduction#
In this guide, you will learn how to configure a predictor for a trained model.
Warning
This guide assumes that a model has already been trained and saved into the Model Registry. To learn how to create a model in the Model Registry, see Model Registry Guide
Predictors are the main component of deployments. They are responsible for running a model server that loads a trained model, handles inference requests and returns predictions. They can be configured to use different model servers, serving tools, log specific inference data or scale differently. In each predictor, you can configure the following components:
GUI#
Step 1: Create new deployment#
If you have at least one model already trained and saved in the Model Registry, navigate to the deployments page by clicking on the Deployments tab on the navigation menu on the left.
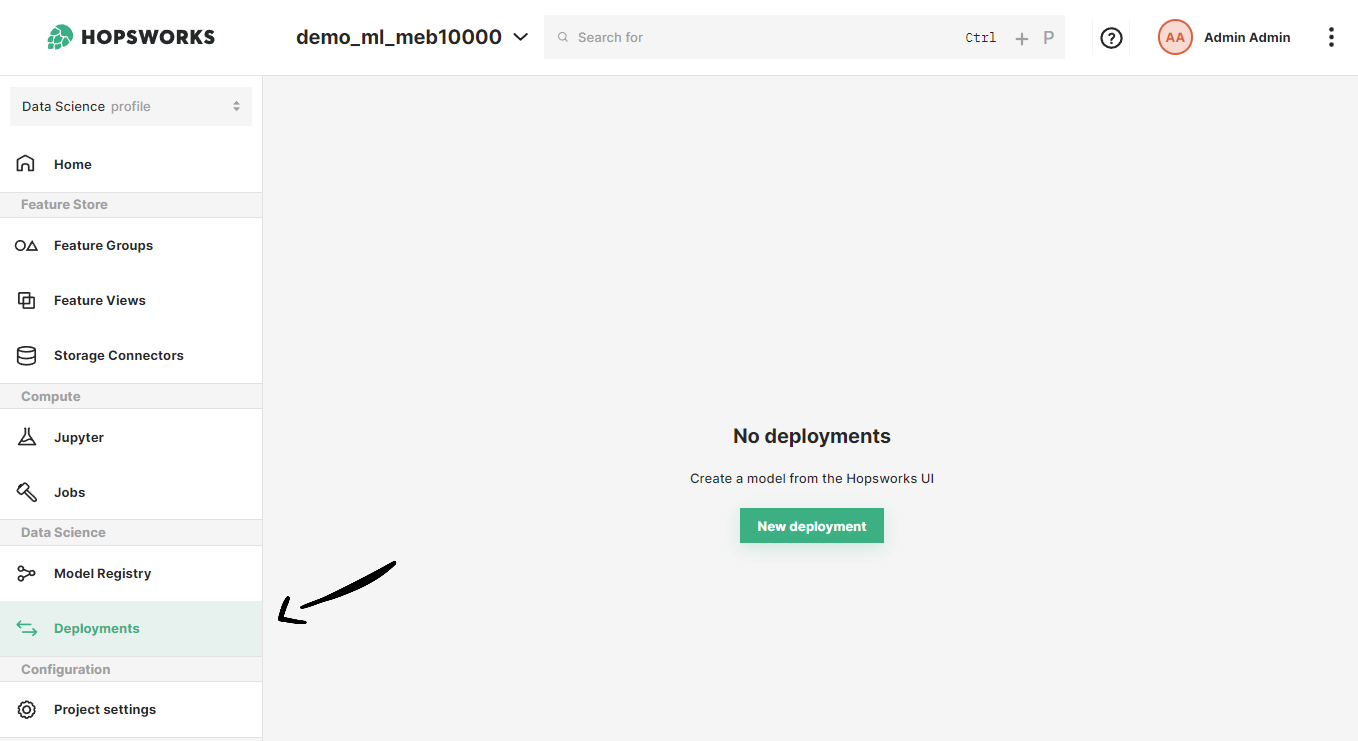
Once in the deployments page, click on New deployment if there are not existing deployments or on Create new deployment at the top-right corner to open the deployment creation form.
Step 2: Choose a model server#
A simplified creation form will appear, including the most common deployment fields among all the configuration possible. These fields include the model server and custom script (for python models).
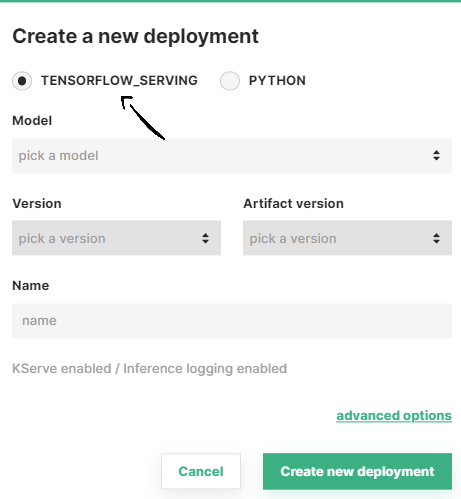
Moreover, you can optionally select a predictor script (see Step 3), enable KServe (see Step 4) or change other advanced configuration (see Step 5). Otherwise, click on Create new deployment to create the deployment for your model.
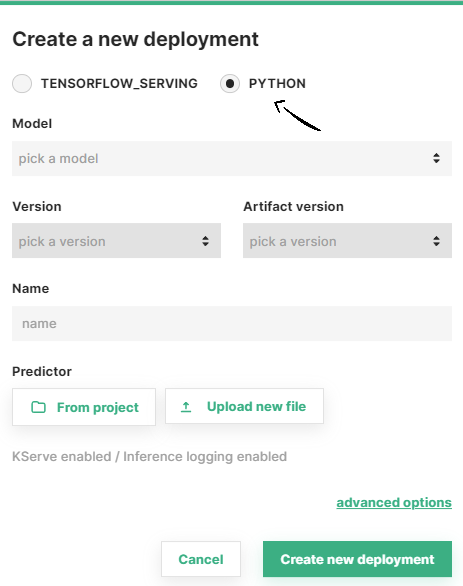
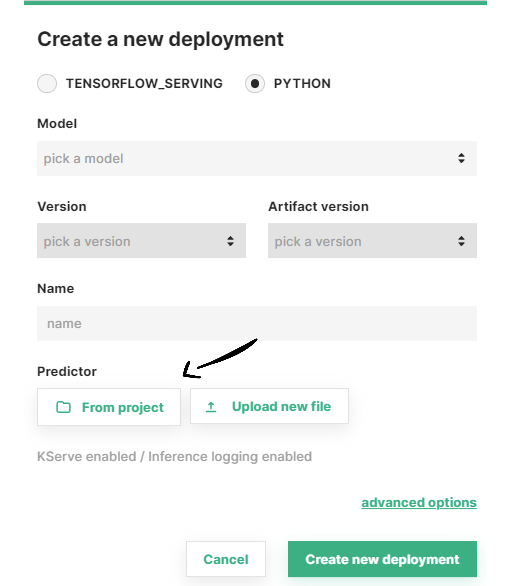
Step 3 (Optional): Select a predictor script#
For python models, if you want to use your own predictor script click on From project and navigate through the file system to find it, or click on Upload new file to upload a predictor script now.
Step 4 (Optional): Enable KServe#
Other configuration such as the serving tool, is part of the advanced options of a deployment. To navigate to the advanced creation form, click on Advanced options.
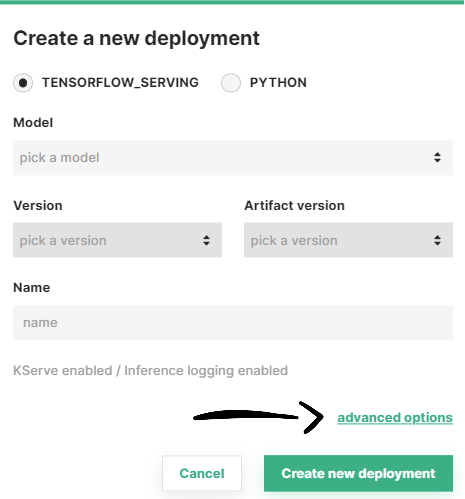
Here, you change the serving tool for your deployment by enabling or disabling the KServe checkbox.
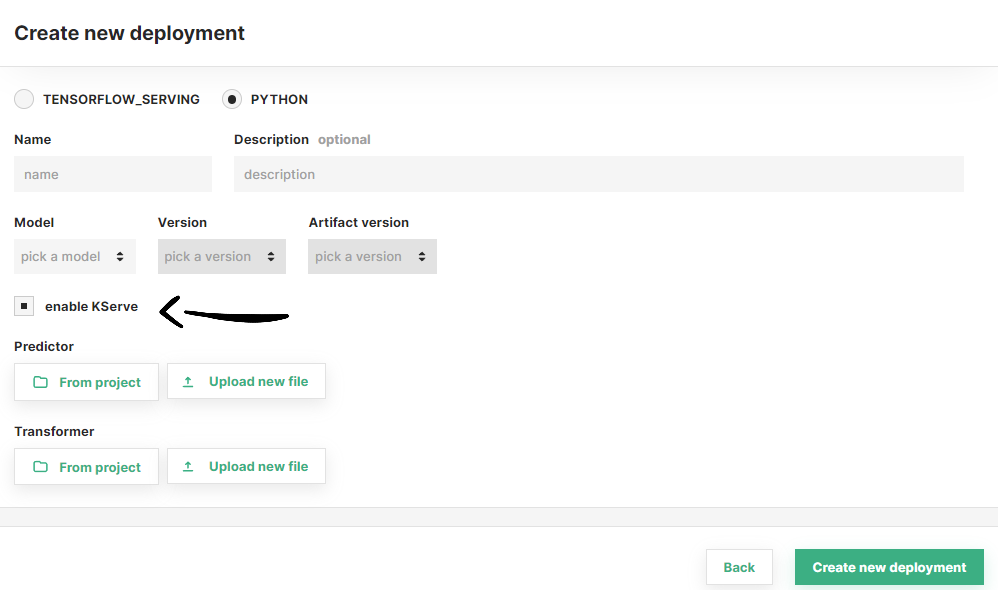
Step 5 (Optional): Other advanced options#
Additionally, you can adjust the default values of the rest of components:
Predictor components
Once you are done with the changes, click on Create new deployment at the bottom of the page to create the deployment for your model.
Code#
Step 1: Connect to Hopsworks#
import hopsworks
project = hopsworks.login()
# get Hopsworks Model Registry handle
mr = project.get_model_registry()
# get Hopsworks Model Serving handle
ms = project.get_model_serving()
Step 2 (Optional): Implement predictor script#
class Predict(object):
def __init__(self):
""" Initialization code goes here:
- Download the model artifact
- Load the model
"""
pass
def predict(self, inputs):
""" Serve predictions using the trained model"""
pass
Jupyter magic
In a jupyter notebook, you can add %%writefile my_predictor.py at the top of the cell to save it as a local file.
Step 3 (Optional): Upload the script to your project#
You can also use the UI to upload your predictor script. See above
uploaded_file_path = dataset_api.upload("my_predictor.py", "Resources", overwrite=True)
predictor_script_path = os.path.join("/Projects", project.name, uploaded_file_path)
Step 4: Define predictor#
my_model = mr.get_model("my_model", version=1)
my_predictor = ms.create_predictor(my_model,
# optional
model_server="PYTHON",
serving_tool="KSERVE",
script_file=predictor_script_path
)
Step 3: Create a deployment with the predictor#
my_deployment = my_predictor.deploy()
# or
my_deployment = ms.create_deployment(my_predictor)
my_deployment.save()
API Reference#
Model Server#
Hopsworks Model Serving currently supports deploying models with a Flask server for python-based models or TensorFlow Serving for TensorFlow / Keras models. Support for TorchServe for running PyTorch models is coming soon. Today, you can deploy PyTorch models as python-based models.
Show supported model servers
| Model Server | Supported | ML Frameworks |
|---|---|---|
| Flask | ✅ | python-based (scikit-learn, xgboost, pytorch...) |
| TensorFlow Serving | ✅ | keras, tensorflow |
| TorchServe | ❌ | pytorch |
Serving tool#
In Hopsworks, model servers can be deployed in three different ways: directly on Docker, on Kubernetes deployments or using KServe inference services. Although the same models can be deployed in either of our two serving tools (Python or KServe), the use of KServe is highly recommended. The following is a comparitive table showing the features supported by each of them.
Show serving tools comparison
| Feature / requirement | Docker | Kubernetes (enterprise) | KServe (enterprise) |
|---|---|---|---|
| Autoscaling (scale-out) | ❌ | ✅ | ✅ |
| Resource allocation | ➖ fixed | ➖ min. resources | ✅ min / max. resources |
| Inference logging | ➖ simple | ➖ simple | ✅ fine-grained |
| Inference batching | ➖ partially | ➖ partially | ✅ |
| Scale-to-zero | ❌ | ❌ | ✅ after 30s of inactivity) |
| Transformers | ❌ | ❌ | ✅ |
| Low-latency predictions | ❌ | ❌ | ✅ |
| Multiple models | ❌ | ❌ | ➖ (python-based) |
| Custom predictor required (python-only) |
✅ | ✅ | ❌ |
Custom script#
Depending on the model server and serving tool used in the deployment, you can provide your own python script to load the model and make predictions.
Show supported custom predictors
| Serving tool | Model server | Custom predictor script |
|---|---|---|
| Docker | Flask | ✅ (required) |
| TensorFlow Serving | ❌ | |
| Kubernetes | Flask | ✅ (required) |
| TensorFlow Serving | ❌ | |
| KServe | Flask | ✅ (only required for artifacts with multiple models) |
| TensorFlow Serving | ❌ |
Environment variables#
A number of different environment variables is available in the predictor to ease its implementation.
Show environment variables
| Name | Description |
|---|---|
| ARTIFACT_FILES_PATH | Local path to the model artifact files |
| DEPLOYMENT_NAME | Name of the current deployment |
| MODEL_NAME | Name of the model being served by the current deployment |
| MODEL_VERSION | Version of the model being served by the current deployment |
| ARTIFACT_VERSION | Version of the model artifact being served by the current deployment |
Transformer#
Transformers are used to apply transformations on the model inputs before sending them to the predictor for making predictions using the model. To learn more about transformers, see the Transformer Guide.
Warning
Transformers are only supported in KServe deployments.
Inference logger#
Inference loggers are deployment components that log inference requests into a Kafka topic for later analysis. To learn about the different logging modes, see the Inference Logger Guide
Inference batcher#
Inference batcher are deployment component that apply batching to the incoming inference requests for a better throughput-latency trade-off. To learn about the different configuration available for the inference batcher, see the Inference Batcher Guide.
Resources#
Resources include the number of replicas for the deployment as well as the resources (i.e., memory, CPU, GPU) to be allocated per replica. To learn about the different combinations available, see the Resources Guide.
Conclusion#
In this guide you learned how to configure a predictor.